Detailed information of oriT
oriT
The information of the oriT region
| oriTDB ID | 200306 |
| Name | oriT_ICE_Seq35246_TnGBS2 |
| Organism | Streptococcus equi subsp. zooepidemicus ATCC 35246 |
| Sequence Completeness | - |
| NCBI accession of oriT (coordinates [strand]) | NC_017582 (5428..5460 [-], 33 nt) |
| oriT length | 33 nt |
| IRs (inverted repeats) | _ |
| Location of nic site | _ |
| Conserved sequence flanking the nic site |
_ |
| Note | Predicted by oriTfinder 2.0 |
oriT sequence
Download Length: 33 nt
>oriT_ICE_Seq35246_TnGBS2
GCATGTGTGGCCACACGTGCTACGCTTGCCAGA
GCATGTGTGGCCACACGTGCTACGCTTGCCAGA
Visualization of oriT structure
oriT secondary structure
Predicted by RNAfold.
Download structure file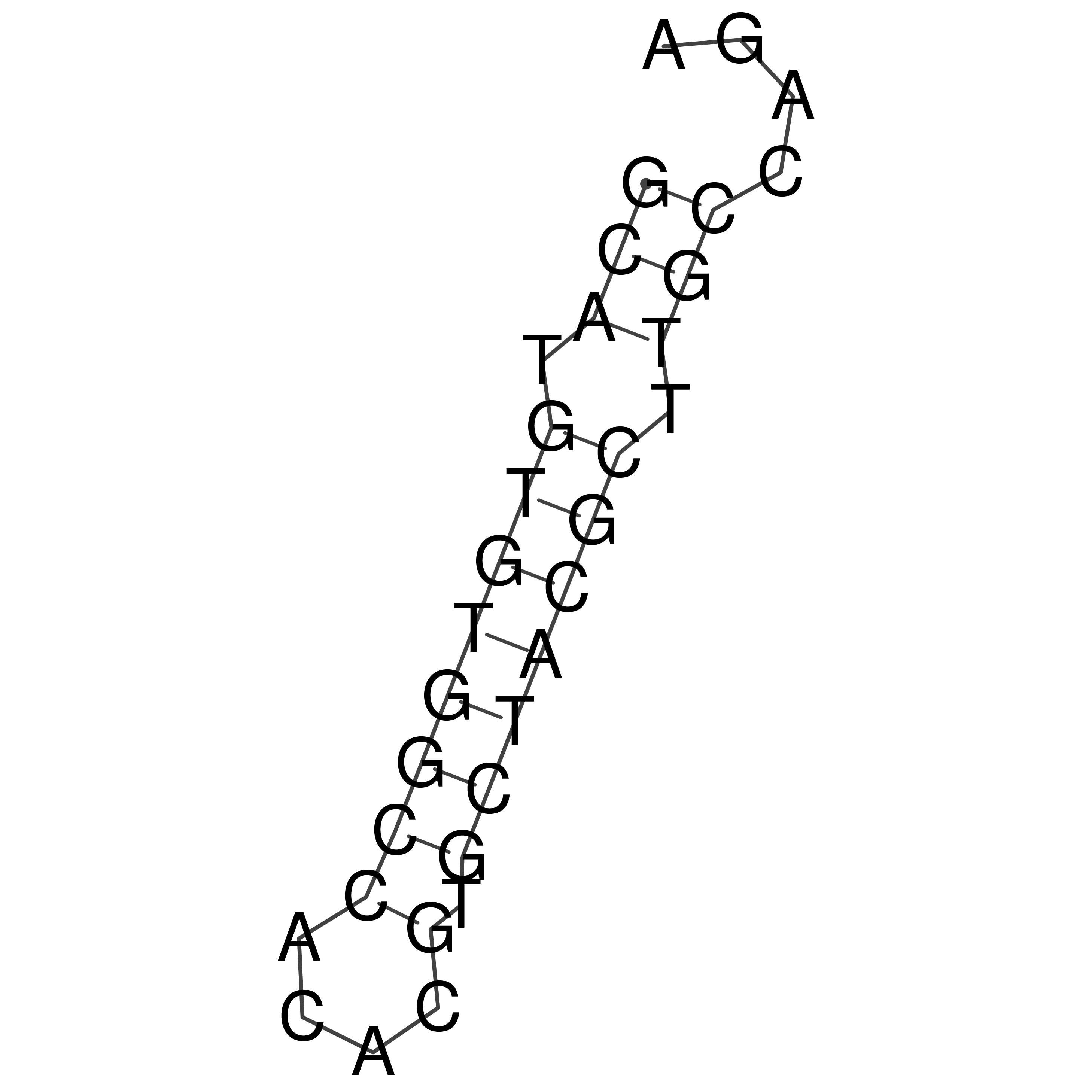
Relaxase
| ID | 14346 | GenBank | WP_038673973 |
| Name | Relaxase_SESEC_RS08945_ICE_Seq35246_TnGBS2 |
UniProt ID | _ |
| Length | 547 a.a. | PDB ID | |
| Note | Predicted by oriTfinder 2.0 | ||
Relaxase protein sequence
Download Length: 547 a.a. Molecular weight: 63939.19 Da Isoelectric Point: 6.6451
>WP_038673973.1 relaxase/mobilization nuclease domain-containing protein [Streptococcus equi]
MVVTKVFQIKQTKNLKRAIDYITRDDATLIKVEQHDKDDAFDYTLTTDGEVHKKLISGHHLIDPGDRDAI
YDDFILLKQSVDDFYDNDTLSDLKNDNRVLAHHIVQSFSPDDNLTPEEVNEIGRKTALEFTGGDYQFVVA
THMDKGFLHNHIIFNTTNEVTLKKFRWQKGTKKSLEHISDKHAELYGAQILKPKLRTSYTDYSAWRRQNN
FSYEIKQRLNFLLKHSISVEDFQQKAKALDLHIDFSGKFTKYRLLVPLDGKLQEKNTRDRTLSKKRIYSL
EQIQKRVAMNEVVYTVDHIKEKYEEEQAKKAEDFEMKVRIEPWQISEITTQSIHLPVAFGLEQKGTVSIP
ARMLDQNEDGSFTAYFKKKDYFYFINPDKSTDNRFIQGGTLVKQLSLNSGEVILTKNWEMTELERLVEEF
NFLSANKVTNSKQFQEMQERFLEQLEKTDQTLAQLDSKVAYLNKVLGALSDYQDGLVPSEVTMAILEKAK
VAQNTDRNLIRKEIKELQIEREALQEARDRIVKDYDFANEMEQSYDHKHHQSKGHQR
MVVTKVFQIKQTKNLKRAIDYITRDDATLIKVEQHDKDDAFDYTLTTDGEVHKKLISGHHLIDPGDRDAI
YDDFILLKQSVDDFYDNDTLSDLKNDNRVLAHHIVQSFSPDDNLTPEEVNEIGRKTALEFTGGDYQFVVA
THMDKGFLHNHIIFNTTNEVTLKKFRWQKGTKKSLEHISDKHAELYGAQILKPKLRTSYTDYSAWRRQNN
FSYEIKQRLNFLLKHSISVEDFQQKAKALDLHIDFSGKFTKYRLLVPLDGKLQEKNTRDRTLSKKRIYSL
EQIQKRVAMNEVVYTVDHIKEKYEEEQAKKAEDFEMKVRIEPWQISEITTQSIHLPVAFGLEQKGTVSIP
ARMLDQNEDGSFTAYFKKKDYFYFINPDKSTDNRFIQGGTLVKQLSLNSGEVILTKNWEMTELERLVEEF
NFLSANKVTNSKQFQEMQERFLEQLEKTDQTLAQLDSKVAYLNKVLGALSDYQDGLVPSEVTMAILEKAK
VAQNTDRNLIRKEIKELQIEREALQEARDRIVKDYDFANEMEQSYDHKHHQSKGHQR
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4CP
| ID | 16838 | GenBank | WP_038673967 |
| Name | t4cp2_SESEC_RS08970_ICE_Seq35246_TnGBS2 |
UniProt ID | _ |
| Length | 681 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 681 a.a. Molecular weight: 78455.05 Da Isoelectric Point: 4.9872
>WP_038673967.1 VirD4-like conjugal transfer protein, CD1115 family [Streptococcus equi]
MELKHKRLLPYLLLSLLLAYLTHRAYVLYWMAPQTDMTNLFAPYTYVFEKITEPPYFYWNTSPLAILSAL
VGFFVGLLFYLKIRLDGNYRHGEESGSARMATAQELKGFQDEEPRNNMIFSREAQMGLFNKRLPFERQLN
KNVLVAGLPGDGKTYNYVKPNLMQMNSSFIVTDPKGVLVREVGTLLKENGYQIKIFDLVNLTNSDMFNPF
KYMTSELDIDRITEAIVEGTKKGDREGEDFWLQAKLLLNRALLGYLYFDSQVRHYEPNLSMVADLLRNLK
RPNEKELSAVEKMFKQLEKSKPGNYACRQWELFNSNFEAETRTSVLAIVATQYSIFDHDAVTNLIKTDTM
EMDTWNTEKTAVFVAISETNKAYSFLASTFFTVVFDQLTHSADAIIQGEKKGYELEDLLHVQFIFDEFAN
CGKIPHFNEVLASIRSREMSIKIIIQAISQLDTLYGVPARKSMVNNCATLLFLGTNDEDTMKYFSMRAGK
QTITQTSYSEQRGQRRTGTTSHQAHQRDLMTPDEIARIGVDEALVFISKQNVFRDKKAMVSNHPMKDWLA
NHYQDKTWYHYKRFMEEGAEFIDAVMTGQIPEDHIWAPDMSDYQAFLEENGFDNTRQSAPETSVHDQVPV
TNPEMPSESPSQTPETSKKLVDMDTGEIFELPPEDREDFGEISFEDQRVEV
MELKHKRLLPYLLLSLLLAYLTHRAYVLYWMAPQTDMTNLFAPYTYVFEKITEPPYFYWNTSPLAILSAL
VGFFVGLLFYLKIRLDGNYRHGEESGSARMATAQELKGFQDEEPRNNMIFSREAQMGLFNKRLPFERQLN
KNVLVAGLPGDGKTYNYVKPNLMQMNSSFIVTDPKGVLVREVGTLLKENGYQIKIFDLVNLTNSDMFNPF
KYMTSELDIDRITEAIVEGTKKGDREGEDFWLQAKLLLNRALLGYLYFDSQVRHYEPNLSMVADLLRNLK
RPNEKELSAVEKMFKQLEKSKPGNYACRQWELFNSNFEAETRTSVLAIVATQYSIFDHDAVTNLIKTDTM
EMDTWNTEKTAVFVAISETNKAYSFLASTFFTVVFDQLTHSADAIIQGEKKGYELEDLLHVQFIFDEFAN
CGKIPHFNEVLASIRSREMSIKIIIQAISQLDTLYGVPARKSMVNNCATLLFLGTNDEDTMKYFSMRAGK
QTITQTSYSEQRGQRRTGTTSHQAHQRDLMTPDEIARIGVDEALVFISKQNVFRDKKAMVSNHPMKDWLA
NHYQDKTWYHYKRFMEEGAEFIDAVMTGQIPEDHIWAPDMSDYQAFLEENGFDNTRQSAPETSVHDQVPV
TNPEMPSESPSQTPETSKKLVDMDTGEIFELPPEDREDFGEISFEDQRVEV
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4SS
T4SS were predicted by using oriTfinder2.
Region 1: 1893966..1909275
| Locus tag | Coordinates | Strand | Size (bp) | Protein ID | Product | Description |
|---|---|---|---|---|---|---|
| SESEC_RS08970 (SeseC_02291) | 1891921..1893966 | - | 2046 | WP_038673967 | VirD4-like conjugal transfer protein, CD1115 family | - |
| SESEC_RS08975 (SeseC_02292) | 1893966..1894457 | - | 492 | WP_014623487 | DUF3801 domain-containing protein | cd411 |
| SESEC_RS08980 (SeseC_02293) | 1894479..1895261 | - | 783 | WP_014623488 | hypothetical protein | - |
| SESEC_RS08985 (SeseC_02294) | 1895261..1895533 | - | 273 | WP_014623489 | hypothetical protein | - |
| SESEC_RS08990 (SeseC_02295) | 1895555..1896157 | - | 603 | WP_038673964 | hypothetical protein | prgL |
| SESEC_RS08995 (SeseC_02296) | 1896181..1898877 | - | 2697 | WP_014623491 | phage tail tip lysozyme | prgK |
| SESEC_RS10695 (SeseC_02297) | 1898910..1899440 | + | 531 | WP_154224853 | hypothetical protein | - |
| SESEC_RS09010 (SeseC_02298) | 1899634..1901985 | - | 2352 | WP_014623493 | VirB4-like conjugal transfer ATPase, CD1110 family | virb4 |
| SESEC_RS09015 (SeseC_02299) | 1901966..1902325 | - | 360 | WP_037582122 | hypothetical protein | - |
| SESEC_RS10970 (SeseC_02300) | 1902681..1902914 | - | 234 | WP_014623495 | hypothetical protein | - |
| SESEC_RS09025 (SeseC_02301) | 1903075..1903827 | - | 753 | WP_014623496 | hypothetical protein | prgHb |
| SESEC_RS09030 (SeseC_02302) | 1903876..1904442 | - | 567 | WP_014623497 | hypothetical protein | - |
| SESEC_RS09035 (SeseC_02303) | 1904547..1904774 | - | 228 | WP_000447009 | hypothetical protein | - |
| SESEC_RS09040 (SeseC_02304) | 1905051..1908572 | - | 3522 | WP_014623499 | SspB-related isopeptide-forming adhesin | prgB |
| SESEC_RS09045 (SeseC_02305) | 1908637..1909275 | - | 639 | WP_038673957 | LPXTG cell wall anchor domain-containing protein | prgC |
| SESEC_RS09050 (SeseC_02306) | 1909290..1909589 | - | 300 | WP_038673954 | hypothetical protein | - |
| SESEC_RS09055 (SeseC_02309) | 1909957..1912242 | - | 2286 | WP_038673952 | C39 family peptidase | - |
| SESEC_RS09060 (SeseC_02310) | 1912280..1912606 | - | 327 | WP_014623503 | single-stranded DNA-binding protein | - |
| SESEC_RS09065 (SeseC_02311) | 1912603..1913691 | - | 1089 | WP_014623504 | replication initiator protein A | - |
| SESEC_RS09070 (SeseC_02312) | 1913692..1913877 | - | 186 | WP_014623505 | hypothetical protein | - |
| SESEC_RS09075 (SeseC_02314) | 1913946..1914233 | - | 288 | Protein_1764 | hypothetical protein | - |
Host bacterium
| ID | 274 | Element type | ICE (Integrative and conjugative element) |
| Element name | ICE_Seq35246_TnGBS2 | GenBank | NC_017582 |
| Element size | 2167264 bp | Coordinate of oriT [Strand] | 5428..5460 [-] |
| Host bacterium | Streptococcus equi subsp. zooepidemicus ATCC 35246 | Coordinate of element | 1882597..1914385 |
Cargo genes
| Drug resistance gene | - |
| Virulence gene | - |
| Metal resistance gene | - |
| Degradation gene | - |
| Symbiosis gene | - |
| Anti-CRISPR | AcrIIA21 |