Detailed information of oriT
oriT
The information of the oriT region
| oriTDB ID | 120559 |
| Name | oriT_pRHBSTW-00054_3 |
| Organism | Klebsiella grimontii strain RHBSTW-00054 |
| Sequence Completeness | - |
| NCBI accession of oriT (coordinates [strand]) | NZ_CP055414 (20120..20169 [+], 50 nt) |
| oriT length | 50 nt |
| IRs (inverted repeats) | 7..14, 17..24 (GCAAAATT..AATTTTGC) |
| Location of nic site | 33..34 |
| Conserved sequence flanking the nic site |
GGTGTGGTGA |
| Note | Predicted by oriTfinder 2.0 |
oriT sequence
Download Length: 50 nt
>oriT_pRHBSTW-00054_3
AAATCTGCAAAATTTTAATTTTGCGTGGGGTGTGGTGATTTTGTGGTGAG
AAATCTGCAAAATTTTAATTTTGCGTGGGGTGTGGTGATTTTGTGGTGAG
Visualization of oriT structure
oriT secondary structure
Predicted by RNAfold.
Download structure file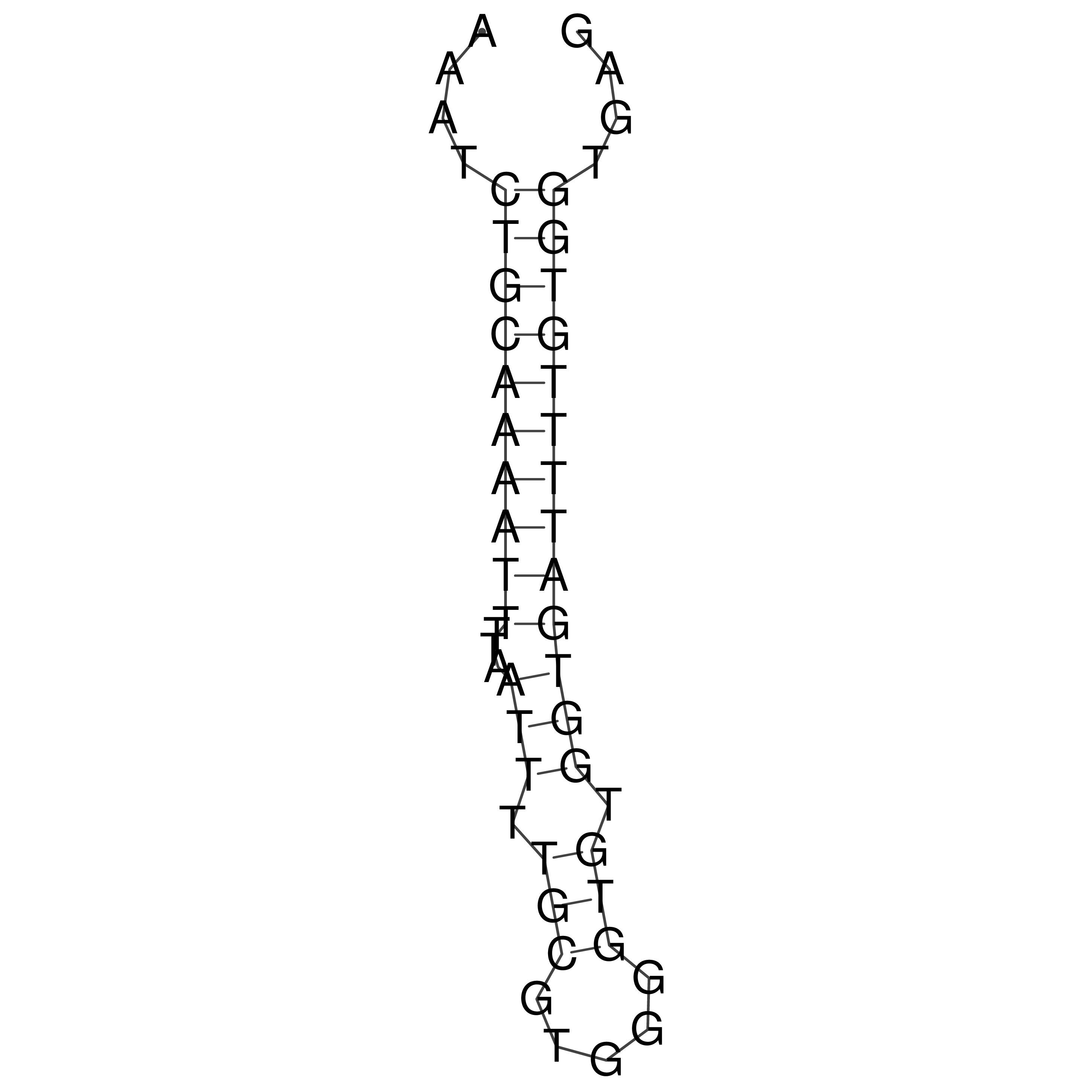
Relaxase
| ID | 12951 | GenBank | WP_154931245 |
| Name | traI_HV046_RS30675_pRHBSTW-00054_3 |
UniProt ID | _ |
| Length | 1753 a.a. | PDB ID | |
| Note | Predicted by oriTfinder 2.0 | ||
Relaxase protein sequence
Download Length: 1753 a.a. Molecular weight: 190731.80 Da Isoelectric Point: 6.1730
>WP_154931245.1 MULTISPECIES: conjugative transfer relaxase/helicase TraI [Klebsiella]
MMSIGSVKSAGSAGNYYTDKDNYYVIGSMDERWQGKGAEALGIDGKAVDKALFTELLKGKLPDGSDLTRI
QDGANRHRPGYDLTFSAPKSVSVMAMLGGDKRLIDAHNQAVTEAVRQLETLAATRVMTDGKSETVLTGNL
IVAKFNHDTNRNQEPQIHTHAVVINATQNGDKWQSLGTDKIGKTGFIENVYANQIAFGKLYREAFKPLVE
KLGYETEVVGKHGMWEMKGVPVEPFSTRSQEVREAAGPDASLKSRDVAALDTRKSKEAIDPAEKMVEWMN
TLKETGFDIRGYREAADARAAELARAPAAPVNTDGPDITDVVTKAIAGLSDRKVQFTYADLLARTVGQLE
AKDGVFDLARKGIDAAIEREQLIPLDREKGLFTSNIHVLDELAVKALSQEVQRQNHVSVTPDASVVRQVP
FSDAVSVLAQDRLVMGIVSGQGGATGQRERVAELTLMAREQGRDVHILAADNRSRDFLAGDVRLAGETVT
GKSALQDGTAFIPGGTLIVDQAEKLSLKETISLLDGAMRHNVQVLLSDSGKRSGTGSALTVLKDSGVNTY
RWQGGQQTTADIISEPDKGARYSRLAQEFAVSVREGQESVAQISGTREQSVLNGLIRDSLRQEGVLGEKD
TTITALTPVWLDSKSRGVRDYYREGMVMERWDPENRTHDRFVIDRVTASSNMLTLKDRDGVRLDLKVSAV
DSQWTLFRADTLPVAEGERLAVLGKIPDTRLKGGESVTVMKVEDGQLTVQRPGQKTTQTLAVGAGVFDGI
KVGHGWVESPGRSVSETATVFASVTQRELDNATLNQLAQSGSHLRLYSAQDAARTTEKLSRHTAFSVVSE
QLKTRSGETDLDAAIAQQKAGLRTPAEQAIHLAIPLLESEKLTFSRPQLLATALETGGGKVPMADIDTTI
QAQIRSGQLLNVPVAHGYGNDLLISRQTWDAEKSILTHVLEGKDAVAPLMDRVPASLMTDLTAGQRAATR
MILESTDRFTVVQGYAGVGKTTQFRAVMSAISLLPEETRPRVIGLAPTHRAVGEMQSAGVDARTTASFLH
DTQLLQRNGQTPDFSNTLFLLDESSMVGLADMAKAHSLIVAGGGRAVSSGDNDQLQPIAPGQPFRLMQQR
SAADVAIMKEIVRQMPELRPAVYSLIERDVHLALTTIEQVTPEQVPRKEGAWAPGSSVVEFTPKQEKAIE
KALSEGKTLPEGQPATLYEALVKDYTGRTPEAQSQTLVITHLNKDRRALNSLIHDARRENGETGKEEITL
PVLVTSNIRDGELRKLSTWTAHKEAVALVDNVYHRISKVDKDNQLITLTDSEGKERYISPREASAEGVTL
YRQEKITVSQGDRMRFSKSDPERGYVANSIWEVQSVSGDSVTLSDGKLTRTLTPKAEQAQQHIDLAYAIT
AHGAQGASEPYAIALEGVAGGREQMASFESAYVALSRMKQHVQVYTDSREGWIKAIKNSPEKATAHDILE
PRNDRAVKTADLLFGRARPLDETAAGRAALQQSGLAQGSSPGKFISPGKKYPQPHVALPAFDKNGKAAGI
WLSPLTDRDGRLEAIGGEGRIMGNEDARFVALQNSRNGESLLAGNMGEGVRMARDNPDTGVVVRLAGDDR
PWNPGAITGGRIWAEPAPVAPVPQTGADIILPPEVLAQRAAEEQQRREMEKQAEQTAREVAGEARKAGEP
ADRVKEVIGDVIRGLERDRPGTEKTTLPDDPQFRRQEEAIQQVASERLQRERLQAVERDMVRDLNREKTL
GGD
MMSIGSVKSAGSAGNYYTDKDNYYVIGSMDERWQGKGAEALGIDGKAVDKALFTELLKGKLPDGSDLTRI
QDGANRHRPGYDLTFSAPKSVSVMAMLGGDKRLIDAHNQAVTEAVRQLETLAATRVMTDGKSETVLTGNL
IVAKFNHDTNRNQEPQIHTHAVVINATQNGDKWQSLGTDKIGKTGFIENVYANQIAFGKLYREAFKPLVE
KLGYETEVVGKHGMWEMKGVPVEPFSTRSQEVREAAGPDASLKSRDVAALDTRKSKEAIDPAEKMVEWMN
TLKETGFDIRGYREAADARAAELARAPAAPVNTDGPDITDVVTKAIAGLSDRKVQFTYADLLARTVGQLE
AKDGVFDLARKGIDAAIEREQLIPLDREKGLFTSNIHVLDELAVKALSQEVQRQNHVSVTPDASVVRQVP
FSDAVSVLAQDRLVMGIVSGQGGATGQRERVAELTLMAREQGRDVHILAADNRSRDFLAGDVRLAGETVT
GKSALQDGTAFIPGGTLIVDQAEKLSLKETISLLDGAMRHNVQVLLSDSGKRSGTGSALTVLKDSGVNTY
RWQGGQQTTADIISEPDKGARYSRLAQEFAVSVREGQESVAQISGTREQSVLNGLIRDSLRQEGVLGEKD
TTITALTPVWLDSKSRGVRDYYREGMVMERWDPENRTHDRFVIDRVTASSNMLTLKDRDGVRLDLKVSAV
DSQWTLFRADTLPVAEGERLAVLGKIPDTRLKGGESVTVMKVEDGQLTVQRPGQKTTQTLAVGAGVFDGI
KVGHGWVESPGRSVSETATVFASVTQRELDNATLNQLAQSGSHLRLYSAQDAARTTEKLSRHTAFSVVSE
QLKTRSGETDLDAAIAQQKAGLRTPAEQAIHLAIPLLESEKLTFSRPQLLATALETGGGKVPMADIDTTI
QAQIRSGQLLNVPVAHGYGNDLLISRQTWDAEKSILTHVLEGKDAVAPLMDRVPASLMTDLTAGQRAATR
MILESTDRFTVVQGYAGVGKTTQFRAVMSAISLLPEETRPRVIGLAPTHRAVGEMQSAGVDARTTASFLH
DTQLLQRNGQTPDFSNTLFLLDESSMVGLADMAKAHSLIVAGGGRAVSSGDNDQLQPIAPGQPFRLMQQR
SAADVAIMKEIVRQMPELRPAVYSLIERDVHLALTTIEQVTPEQVPRKEGAWAPGSSVVEFTPKQEKAIE
KALSEGKTLPEGQPATLYEALVKDYTGRTPEAQSQTLVITHLNKDRRALNSLIHDARRENGETGKEEITL
PVLVTSNIRDGELRKLSTWTAHKEAVALVDNVYHRISKVDKDNQLITLTDSEGKERYISPREASAEGVTL
YRQEKITVSQGDRMRFSKSDPERGYVANSIWEVQSVSGDSVTLSDGKLTRTLTPKAEQAQQHIDLAYAIT
AHGAQGASEPYAIALEGVAGGREQMASFESAYVALSRMKQHVQVYTDSREGWIKAIKNSPEKATAHDILE
PRNDRAVKTADLLFGRARPLDETAAGRAALQQSGLAQGSSPGKFISPGKKYPQPHVALPAFDKNGKAAGI
WLSPLTDRDGRLEAIGGEGRIMGNEDARFVALQNSRNGESLLAGNMGEGVRMARDNPDTGVVVRLAGDDR
PWNPGAITGGRIWAEPAPVAPVPQTGADIILPPEVLAQRAAEEQQRREMEKQAEQTAREVAGEARKAGEP
ADRVKEVIGDVIRGLERDRPGTEKTTLPDDPQFRRQEEAIQQVASERLQRERLQAVERDMVRDLNREKTL
GGD
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4CP
| ID | 15206 | GenBank | WP_048235023 |
| Name | traD_HV046_RS30680_pRHBSTW-00054_3 |
UniProt ID | _ |
| Length | 770 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 770 a.a. Molecular weight: 85941.02 Da Isoelectric Point: 5.1149
>WP_048235023.1 MULTISPECIES: type IV conjugative transfer system coupling protein TraD [Enterobacterales]
MSFNAKDMTQGGQIANMRFRMFGQIANIIFYVLFILFWVLCGLMLMYRLSWQTFVNGCVYWWCTTLGPMR
DIIRSQPVYTIQYYGQSLEYTSEQILADKYTIWCGEQLWTSFVFAAVVSLVICIVTFFIASWVLGRQGKQ
QSEDENTGGRQLSDKPKEVARQMKRDGMASDIKIGDLPILKNSEIQNFCLHGTVGSGKSEVIRRLLNYVR
ARGDMAIIYDRSCEFVKSYYDPSLDKILNPLDSRCAAWDLWKECLTLPDFDNISNTLIPMGTKEDPFWQG
SGRTIFAEGAYLMREDKDRSYEKLVDTMLSIKIDKLRAYLQNTPAANLVEEKIEKTAISIRAVLTNYVKA
IRYLQGIEKNGEPFTIRDWMRGVREDRPNGWLFISSNADTHASLKPVISMWLSIAIRGLLAMGENRNRRV
WIFADELPTLHKLPDLVEILPEARKFGGCYVFGIQSYAQLEDIYGVKPAATLFDVMNTRAFFRSPSKEIA
EFAAGEIGEKEILKASEQYSYGADPVRDGVSTGKEKERETLVSYSDIQTLPDLSCYVTLPGPYPAVKLAL
KYKPRPKIAEGFIPRTLDARVDARLSALLEAREAEGSLARALFTPDAPASGPADTNSHAGEQPEPVSQPA
PADMTVSPAPVKAPPTTKMPAEEPSVRSTEPSALRLTTVPLIKPKAAAAAAAAATVSSAGTPAAAAGGTE
QELAQQSAEQGQDMLPAGMNEDGVIEDMQAYDAWLADEQTQRDMQRREEVNINHSHRHDEQDNVEIGGNF
MSFNAKDMTQGGQIANMRFRMFGQIANIIFYVLFILFWVLCGLMLMYRLSWQTFVNGCVYWWCTTLGPMR
DIIRSQPVYTIQYYGQSLEYTSEQILADKYTIWCGEQLWTSFVFAAVVSLVICIVTFFIASWVLGRQGKQ
QSEDENTGGRQLSDKPKEVARQMKRDGMASDIKIGDLPILKNSEIQNFCLHGTVGSGKSEVIRRLLNYVR
ARGDMAIIYDRSCEFVKSYYDPSLDKILNPLDSRCAAWDLWKECLTLPDFDNISNTLIPMGTKEDPFWQG
SGRTIFAEGAYLMREDKDRSYEKLVDTMLSIKIDKLRAYLQNTPAANLVEEKIEKTAISIRAVLTNYVKA
IRYLQGIEKNGEPFTIRDWMRGVREDRPNGWLFISSNADTHASLKPVISMWLSIAIRGLLAMGENRNRRV
WIFADELPTLHKLPDLVEILPEARKFGGCYVFGIQSYAQLEDIYGVKPAATLFDVMNTRAFFRSPSKEIA
EFAAGEIGEKEILKASEQYSYGADPVRDGVSTGKEKERETLVSYSDIQTLPDLSCYVTLPGPYPAVKLAL
KYKPRPKIAEGFIPRTLDARVDARLSALLEAREAEGSLARALFTPDAPASGPADTNSHAGEQPEPVSQPA
PADMTVSPAPVKAPPTTKMPAEEPSVRSTEPSALRLTTVPLIKPKAAAAAAAAATVSSAGTPAAAAGGTE
QELAQQSAEQGQDMLPAGMNEDGVIEDMQAYDAWLADEQTQRDMQRREEVNINHSHRHDEQDNVEIGGNF
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
Host bacterium
| ID | 20988 | GenBank | NZ_CP055414 |
| Plasmid name | pRHBSTW-00054_3 | Incompatibility group | IncR |
| Plasmid size | 129961 bp | Coordinate of oriT [Strand] | 20120..20169 [+] |
| Host baterium | Klebsiella grimontii strain RHBSTW-00054 |
Cargo genes
| Drug resistance gene | - |
| Virulence gene | - |
| Metal resistance gene | - |
| Degradation gene | - |
| Symbiosis gene | - |
| Anti-CRISPR | AcrIE9 |