Detailed information of oriT
oriT
The information of the oriT region
| oriTDB ID | 120276 |
| Name | oriT_CGMCC 11640|unnamed |
| Organism | Bacillus velezensis strain CGMCC 11640 |
| Sequence Completeness | - |
| NCBI accession of oriT (coordinates [strand]) | NZ_CP026611 (14489..14850 [+], 362 nt) |
| oriT length | 362 nt |
| IRs (inverted repeats) | 291..296, 302..307 (AAAAAG..CTTTTT) 188..193, 198..203 (CACCAT..ATGGTG) 171..178, 180..187 (AAACCGCA..TGCGGTTT) 105..110, 117..122 (TTTATG..CATAAA) 62..69, 73..80 (CATAAATT..AATTTATG) 29..34, 38..43 (ATTTCA..TGAAAT) |
| Location of nic site | 111..112 |
| Conserved sequence flanking the nic site |
TATGGTTACA |
| Note | Predicted by oriTfinder 2.0 |
oriT sequence
Download Length: 362 nt
>oriT_CGMCC 11640|unnamed
AAAGAGCGATCTCGTCATCGGGGATTAGATTTCAAGGTGAAATACAGTTGATTGTCGTGAGCATAAATTGAAAATTTATGTGCTTTTTGATTTAAATCACCTAATTTATGGTTACACATAAACATTTTGTTTATGTGCATTGGGCAATAAATCTGGTACCACGACAAAACAAACCGCACTGCGGTTTCACCATGGGAATGGTGCCAGTTTCCCCTTATGCTCTTTCCTTTTCCACCCCCTCCTTCCTTCGGAATCGGGGGCCGGTTTTTTGCTGCCGCAAAAAACCTTGGAAAAAGAAACACTTTTTTTGAACAGATCATTGCAAAATAAAGTGCCAAAACTGATTAAAAGGAGCGTTCACA
AAAGAGCGATCTCGTCATCGGGGATTAGATTTCAAGGTGAAATACAGTTGATTGTCGTGAGCATAAATTGAAAATTTATGTGCTTTTTGATTTAAATCACCTAATTTATGGTTACACATAAACATTTTGTTTATGTGCATTGGGCAATAAATCTGGTACCACGACAAAACAAACCGCACTGCGGTTTCACCATGGGAATGGTGCCAGTTTCCCCTTATGCTCTTTCCTTTTCCACCCCCTCCTTCCTTCGGAATCGGGGGCCGGTTTTTTGCTGCCGCAAAAAACCTTGGAAAAAGAAACACTTTTTTTGAACAGATCATTGCAAAATAAAGTGCCAAAACTGATTAAAAGGAGCGTTCACA
Visualization of oriT structure
oriT secondary structure
Predicted by RNAfold.
Download structure file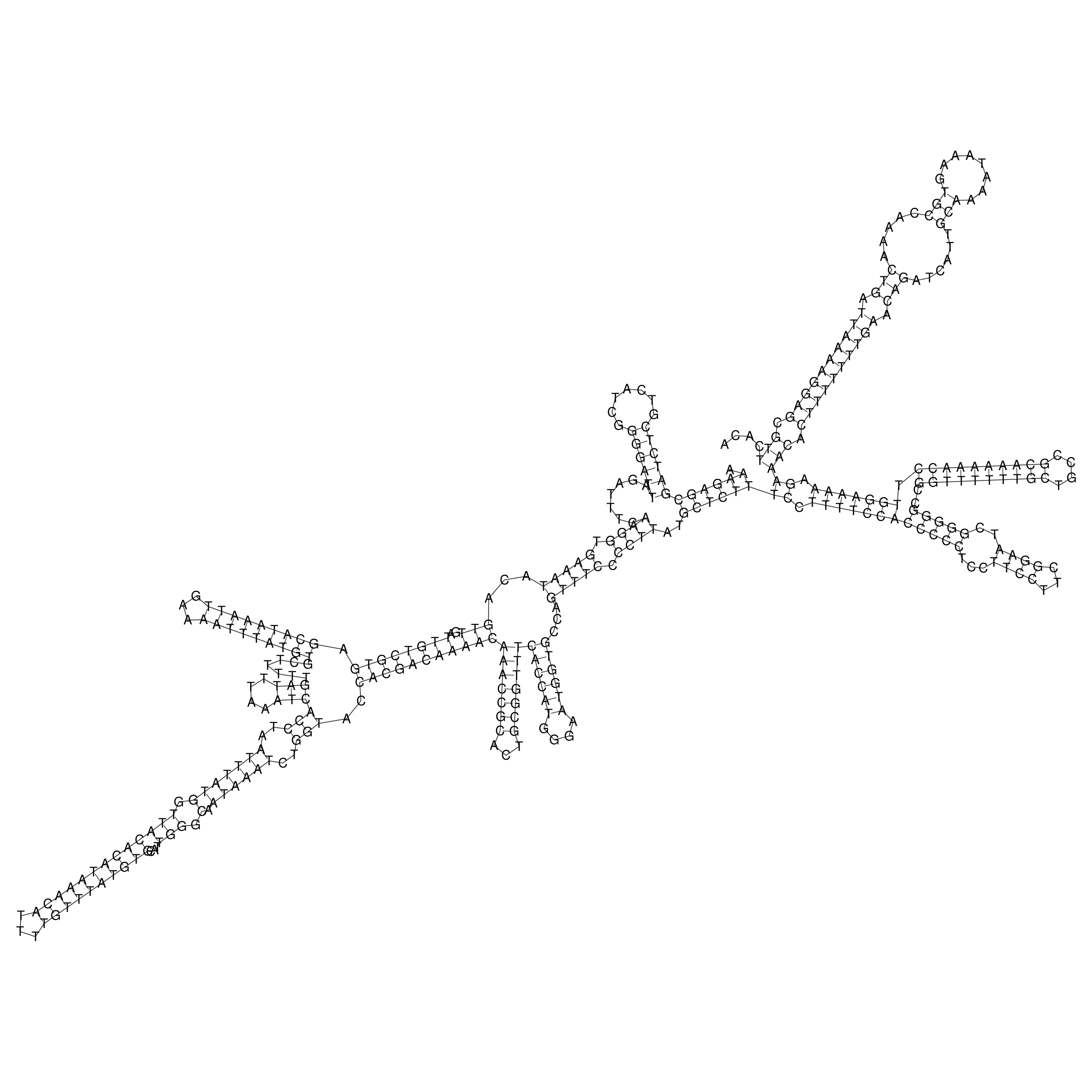
Relaxase
| ID | 12754 | GenBank | WP_073982227 |
| Name | mobP2_C3Z10_RS21685_CGMCC 11640|unnamed |
UniProt ID | _ |
| Length | 410 a.a. | PDB ID | |
| Note | Predicted by oriTfinder 2.0 | ||
Relaxase protein sequence
Download Length: 410 a.a. Molecular weight: 48420.07 Da Isoelectric Point: 9.8706
>WP_073982227.1 MULTISPECIES: MobP2 family relaxase [Bacillus amyloliquefaciens group]
MDAPGVVLVSKYVSGKSTKFSKYVNYINRDEAVRTEKFQTYNVNKLDGYNQYMGNPEKSSGIFTQFKDSL
SPEEKNQLKEIFRQAQENDSVMWQDVISFDNKWLEEHGIYKPNTGWINEGAIQNSIRKGMKVLLKEEQLE
QSGVWSAAIHYNTDNIHVHIALVEPNPTKEYGVFTNKKTGEVYQARRGNRKLKTLDKMKSKVANTLLDRD
KELAKISQLIHDRIAPKGVRFQPRLDTYMSKMYNHIYENLPEDMRLWRYNNNALNFIRPEIDSVITMYIK
KYHPEDFKELDQSLKEEMEFRKSVYGDGPIQVERYKEYRENKHKELYAKLGNSMLKEMVEIRKRESQTKQ
FVRTGTYAPGSASQKQWDAKGKLIKRSDINKIKHALDKDYQSMKNMRKYQQMQYEMEQSR
MDAPGVVLVSKYVSGKSTKFSKYVNYINRDEAVRTEKFQTYNVNKLDGYNQYMGNPEKSSGIFTQFKDSL
SPEEKNQLKEIFRQAQENDSVMWQDVISFDNKWLEEHGIYKPNTGWINEGAIQNSIRKGMKVLLKEEQLE
QSGVWSAAIHYNTDNIHVHIALVEPNPTKEYGVFTNKKTGEVYQARRGNRKLKTLDKMKSKVANTLLDRD
KELAKISQLIHDRIAPKGVRFQPRLDTYMSKMYNHIYENLPEDMRLWRYNNNALNFIRPEIDSVITMYIK
KYHPEDFKELDQSLKEEMEFRKSVYGDGPIQVERYKEYRENKHKELYAKLGNSMLKEMVEIRKRESQTKQ
FVRTGTYAPGSASQKQWDAKGKLIKRSDINKIKHALDKDYQSMKNMRKYQQMQYEMEQSR
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4CP
| ID | 14971 | GenBank | WP_073982219 |
| Name | t4cp2_C3Z10_RS21635_CGMCC 11640|unnamed |
UniProt ID | _ |
| Length | 786 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 786 a.a. Molecular weight: 90647.01 Da Isoelectric Point: 4.8228
>WP_073982219.1 MULTISPECIES: VirD4-like conjugal transfer protein, CD1115 family [Bacillus]
MHKEFKQWKKIFADKYFLIAFTLFCYAAVTCAANFLLHLFKQIPLMLSSFKTFDQSKLSSPFDSYSWKWF
FEFEWDMGIIYGVLYIIASIFIVRQVYRFRIAFRDINKQTKGTARWTTIKEIQETYKAIKDDDIEYEGSA
GMPIVHFNDHLYVDTNSTHTLVVASTQSGKTETYSYPYLDVIMRAKKKDSVVITDIKGDMLKNTHSEFEK
HGYEVMCFNLLNPYWGMAYNPLELVKQAYMKGDFSKAQMLCNTLSYSLFHNDKSHADPMWENASIALVNA
LILAVCDLCIKNGQPENITMYTLTVMLNELGSNPDEDGYTRLDHFFGNLPPSHPAKLQYGTIQFSQGITR
SGIYTGTMAKLKNYTYDTIARMTAQNDLNIEDLAYGEKPVALFIVYPDWDDSNYTIISTFLSQVNAVLSE
KATLSKESTLPRKVRYLFEEVANIPPIEGLNRALAVGLSRGMLYTLVIQNVSQLRDVYGDDMATAIMGNL
GNQIYIMSDEWEDAEKFSEKLGVTTIISADRQGGLMDVDKSYSEREEERPLMLPDELRRLKKGEWVVLRT
KKRENLKRKRVVPYPIFASLDNETHMLHRYEYLMHRFNNEIALGDLGFHGNHETLDLESLLIEFEFNEPV
EQKNKVKGKKRSDKKDADPEVPDYNEIPPPEEPIGIADESSEAMGSLFELVPSDNTNEEEFYEGPCLIDS
SRNEVLEVSEEDAIMNSLEEVYETSTPISDAIKADQYVYIKFFAQKALTEDEYNYFESLTTIEQLRAFFR
APEKHELYEKIKKHIE
MHKEFKQWKKIFADKYFLIAFTLFCYAAVTCAANFLLHLFKQIPLMLSSFKTFDQSKLSSPFDSYSWKWF
FEFEWDMGIIYGVLYIIASIFIVRQVYRFRIAFRDINKQTKGTARWTTIKEIQETYKAIKDDDIEYEGSA
GMPIVHFNDHLYVDTNSTHTLVVASTQSGKTETYSYPYLDVIMRAKKKDSVVITDIKGDMLKNTHSEFEK
HGYEVMCFNLLNPYWGMAYNPLELVKQAYMKGDFSKAQMLCNTLSYSLFHNDKSHADPMWENASIALVNA
LILAVCDLCIKNGQPENITMYTLTVMLNELGSNPDEDGYTRLDHFFGNLPPSHPAKLQYGTIQFSQGITR
SGIYTGTMAKLKNYTYDTIARMTAQNDLNIEDLAYGEKPVALFIVYPDWDDSNYTIISTFLSQVNAVLSE
KATLSKESTLPRKVRYLFEEVANIPPIEGLNRALAVGLSRGMLYTLVIQNVSQLRDVYGDDMATAIMGNL
GNQIYIMSDEWEDAEKFSEKLGVTTIISADRQGGLMDVDKSYSEREEERPLMLPDELRRLKKGEWVVLRT
KKRENLKRKRVVPYPIFASLDNETHMLHRYEYLMHRFNNEIALGDLGFHGNHETLDLESLLIEFEFNEPV
EQKNKVKGKKRSDKKDADPEVPDYNEIPPPEEPIGIADESSEAMGSLFELVPSDNTNEEEFYEGPCLIDS
SRNEVLEVSEEDAIMNSLEEVYETSTPISDAIKADQYVYIKFFAQKALTEDEYNYFESLTTIEQLRAFFR
APEKHELYEKIKKHIE
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
Host bacterium
| ID | 20705 | GenBank | NZ_CP026611 |
| Plasmid name | CGMCC 11640|unnamed | Incompatibility group | - |
| Plasmid size | 62700 bp | Coordinate of oriT [Strand] | 14489..14850 [+] |
| Host baterium | Bacillus velezensis strain CGMCC 11640 |
Cargo genes
| Drug resistance gene | - |
| Virulence gene | - |
| Metal resistance gene | - |
| Degradation gene | - |
| Symbiosis gene | - |
| Anti-CRISPR | - |