Detailed information of oriT
oriT
The information of the oriT region
| oriTDB ID | 116897 |
| Name | oriT_SCAID TST1-2021 (11/270)|unnamed3 |
| Organism | Burkholderia contaminans strain SCAID TST1-2021 (11/270) |
| Sequence Completeness | - |
| NCBI accession of oriT (coordinates [strand]) | NZ_CP082812 (5526..5624 [-], 99 nt) |
| oriT length | 99 nt |
| IRs (inverted repeats) | 24..31, 34..41 (TAACCGGC..GCCGGTTA) |
| Location of nic site | 60..61 |
| Conserved sequence flanking the nic site |
TCCTGCCCGC |
| Note | Predicted by oriTfinder 2.0 |
oriT sequence
Download Length: 99 nt
>oriT_SCAID TST1-2021 (11/270)|unnamed3
GAATAAGGGACAGTGAAGATAGATAACCGGCTCGCCGGTTAGCTAACTTCACACATCCTGCCCGCCTTACGGCGTTAATAACACCAAGGAAAGTCTACA
GAATAAGGGACAGTGAAGATAGATAACCGGCTCGCCGGTTAGCTAACTTCACACATCCTGCCCGCCTTACGGCGTTAATAACACCAAGGAAAGTCTACA
Visualization of oriT structure
oriT secondary structure
Predicted by RNAfold.
Download structure file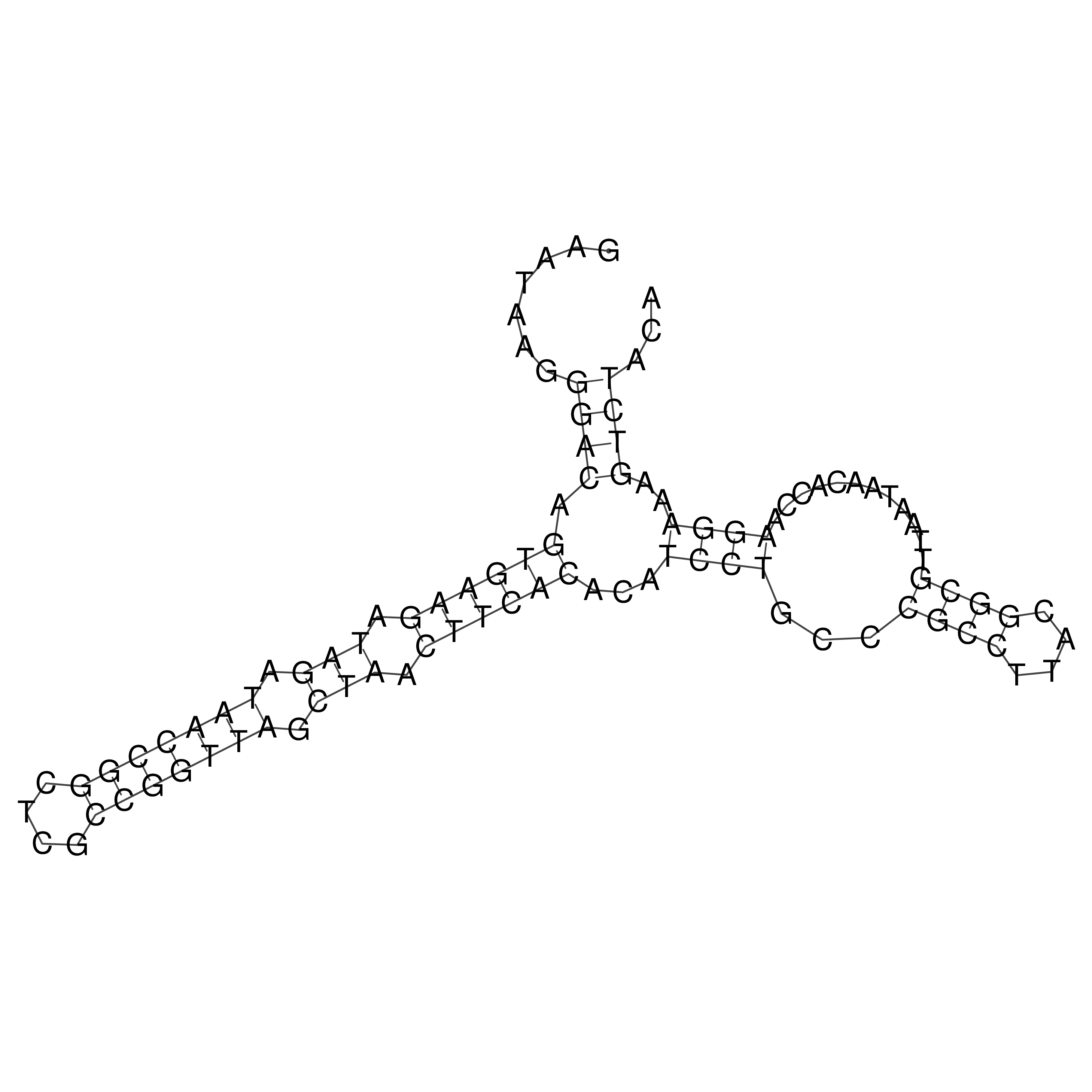
Relaxase
| ID | 10780 | GenBank | WP_011117146 |
| Name | traI_K8B66_RS37795_SCAID TST1-2021 (11/270)|unnamed3 |
UniProt ID | Q937B9 |
| Length | 746 a.a. | PDB ID | |
| Note | Predicted by oriTfinder 2.0 | ||
Relaxase protein sequence
Download Length: 746 a.a. Molecular weight: 82120.82 Da Isoelectric Point: 10.8213
>WP_011117146.1 MULTISPECIES: TraI/MobA(P) family conjugative relaxase [Pseudomonadota]
MIAKHVPMRSLGKSDFAGLANYITDAQSKDHRLGHVQATNCEAGSIQDAITEVLATQHTNTRAKGDKTYH
LIVSFRAGEQPSADTLRAIEERICVGLGYGEHQRISAVHNDTDNLHIHIAINKIHPTRHTMHEPYYPHRA
LAELCTALERDYGLERDNHEPRKRGAEGRAADMERHAGVESLVGWVKRECLDEIKGAQSWQELHQVMRDN
GMELRVRANGLVFEAGDGTMVKASTVARDLSKPSLEARLGPFEASPERQAQTTAKRQYRKDPIRLRVNTV
ELYAKYKAEQQNLTTARAQALERARHRKDRLIEAAKRSNRLRRATIKVVGEGRANKKLLYAQASKALRSE
IQAINKQFQQERTALYAEHRRRTWADWLKKEAQHGGADALAALRAREAAQGLKGNTIRGEGQAKPGHAPA
VDNITKKGTIIFRAGMSAVRDDGDRLQVSREATREGLQEALRLAMQRYGNRITVNGTVEFKAQMIRAAVD
SQLPITFTDPALESRRQALLNKENTHERTERPEHRGRTGRGAGGPGQRPAADQHATGAAAVARAGDGRPA
AGRGDRADAGLHAATVHRKPDVGRLGRKPPPQSQHRLRALSELGVVRIAGGSEVLLPRDVPRHVEQQGTQ
PDHALRRGISRPGTGVGQTPPGVAAADKYIAEREAKRLKGFDIPKHSRYTAGDGALTFQGTRTIEGQALA
LLKRGDEVMVMPIDQATARRLTRIAVGDAVSITAKGSIKTSKGRSR
MIAKHVPMRSLGKSDFAGLANYITDAQSKDHRLGHVQATNCEAGSIQDAITEVLATQHTNTRAKGDKTYH
LIVSFRAGEQPSADTLRAIEERICVGLGYGEHQRISAVHNDTDNLHIHIAINKIHPTRHTMHEPYYPHRA
LAELCTALERDYGLERDNHEPRKRGAEGRAADMERHAGVESLVGWVKRECLDEIKGAQSWQELHQVMRDN
GMELRVRANGLVFEAGDGTMVKASTVARDLSKPSLEARLGPFEASPERQAQTTAKRQYRKDPIRLRVNTV
ELYAKYKAEQQNLTTARAQALERARHRKDRLIEAAKRSNRLRRATIKVVGEGRANKKLLYAQASKALRSE
IQAINKQFQQERTALYAEHRRRTWADWLKKEAQHGGADALAALRAREAAQGLKGNTIRGEGQAKPGHAPA
VDNITKKGTIIFRAGMSAVRDDGDRLQVSREATREGLQEALRLAMQRYGNRITVNGTVEFKAQMIRAAVD
SQLPITFTDPALESRRQALLNKENTHERTERPEHRGRTGRGAGGPGQRPAADQHATGAAAVARAGDGRPA
AGRGDRADAGLHAATVHRKPDVGRLGRKPPPQSQHRLRALSELGVVRIAGGSEVLLPRDVPRHVEQQGTQ
PDHALRRGISRPGTGVGQTPPGVAAADKYIAEREAKRLKGFDIPKHSRYTAGDGALTFQGTRTIEGQALA
LLKRGDEVMVMPIDQATARRLTRIAVGDAVSITAKGSIKTSKGRSR
Protein domains
Predicted by InterproScan.
Protein structure
| Source | ID | Structure |
|---|---|---|
| AlphaFold DB | Q937B9 |
T4CP
| ID | 12595 | GenBank | WP_000694765 |
| Name | t4cp2_K8B66_RS37800_SCAID TST1-2021 (11/270)|unnamed3 |
UniProt ID | _ |
| Length | 637 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 637 a.a. Molecular weight: 69897.09 Da Isoelectric Point: 8.2993
>WP_000694765.1 MULTISPECIES: type IV secretory system conjugative DNA transfer family protein [Bacteria]
MKIKMNNAVGPQVRTAKPKPSKLLPVLGAASMVGGLQAATQFFAHTFAYHATLGPNVGHVYAPWSILHWT
YKWYSQYPDEIMKAGSMGMLVSTVGLLGVAVAKVVTSNSSKANEYLHGSARWAEKKDIQAAGLLPRERNV
LEIVTGKAAPTATGVYVGGWQDKDGNFFYLRHSGPEHVLTYAPTRSGKGVGLVVPTLLSWGASSVITDLK
GELWALTAGWRQKHAKNKVLRFEPASTSGGVCWNPLDEIRLGTEYEVGDVQNLATLIVDPDGKGLDSHWQ
KTAFALLVGVILHALYKAKDDGGTATLPSVDAMLADPNRDIGELWMEMATYGHVDGQNHHAIGSAARDMM
DRPEEEAGSVLSTAKSYLALYRDPVVARNVSRSDFRIKQLMHEDDPVSLYIVTQPNDKARLRPLVRVMVN
MIVRLLADKMDFEGGRPVAHYKHRLLMMLDEFPSLGKLEIMQESLAFVAGYGIKCYLICQDINQLKSRET
GYGHDESITSNCHVQNAYPPNRVETAEHLSRLTGQTTVVKEQITTSGRRTAAMLGQVSRTYQEVQRPLLT
PDECLRMPGPKKNAQGEIEEAGDMVIYVAGYPAIYGKQPLYFKDPVFSARAAIPAPKVSDRLRAVAQAET
EGEGITI
MKIKMNNAVGPQVRTAKPKPSKLLPVLGAASMVGGLQAATQFFAHTFAYHATLGPNVGHVYAPWSILHWT
YKWYSQYPDEIMKAGSMGMLVSTVGLLGVAVAKVVTSNSSKANEYLHGSARWAEKKDIQAAGLLPRERNV
LEIVTGKAAPTATGVYVGGWQDKDGNFFYLRHSGPEHVLTYAPTRSGKGVGLVVPTLLSWGASSVITDLK
GELWALTAGWRQKHAKNKVLRFEPASTSGGVCWNPLDEIRLGTEYEVGDVQNLATLIVDPDGKGLDSHWQ
KTAFALLVGVILHALYKAKDDGGTATLPSVDAMLADPNRDIGELWMEMATYGHVDGQNHHAIGSAARDMM
DRPEEEAGSVLSTAKSYLALYRDPVVARNVSRSDFRIKQLMHEDDPVSLYIVTQPNDKARLRPLVRVMVN
MIVRLLADKMDFEGGRPVAHYKHRLLMMLDEFPSLGKLEIMQESLAFVAGYGIKCYLICQDINQLKSRET
GYGHDESITSNCHVQNAYPPNRVETAEHLSRLTGQTTVVKEQITTSGRRTAAMLGQVSRTYQEVQRPLLT
PDECLRMPGPKKNAQGEIEEAGDMVIYVAGYPAIYGKQPLYFKDPVFSARAAIPAPKVSDRLRAVAQAET
EGEGITI
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
Host bacterium
| ID | 17330 | GenBank | NZ_CP082812 |
| Plasmid name | SCAID TST1-2021 (11/270)|unnamed3 | Incompatibility group | - |
| Plasmid size | 27187 bp | Coordinate of oriT [Strand] | 5526..5624 [-] |
| Host baterium | Burkholderia contaminans strain SCAID TST1-2021 (11/270) |
Cargo genes
| Drug resistance gene | - |
| Virulence gene | - |
| Metal resistance gene | - |
| Degradation gene | - |
| Symbiosis gene | - |
| Anti-CRISPR | - |