Detailed information of oriT
oriT
The information of the oriT region
| oriTDB ID | 114583 |
| Name | oriT_T29|unnamed2 |
| Organism | Agrobacterium sp. T29 |
| Sequence Completeness | - |
| NCBI accession of oriT (coordinates [strand]) | NZ_CP040642 (16473..16501 [+], 29 nt) |
| oriT length | 29 nt |
| IRs (inverted repeats) | 14..19, 24..29 (CGTCGC..GCGACG) |
| Location of nic site | _ |
| Conserved sequence flanking the nic site |
_ |
| Note | Predicted by oriTfinder 2.0 |
oriT sequence
Download Length: 29 nt
>oriT_T29|unnamed2
AGGGCGCAATATACGTCGCTCGCGCGACG
AGGGCGCAATATACGTCGCTCGCGCGACG
Visualization of oriT structure
oriT secondary structure
Predicted by RNAfold.
Download structure file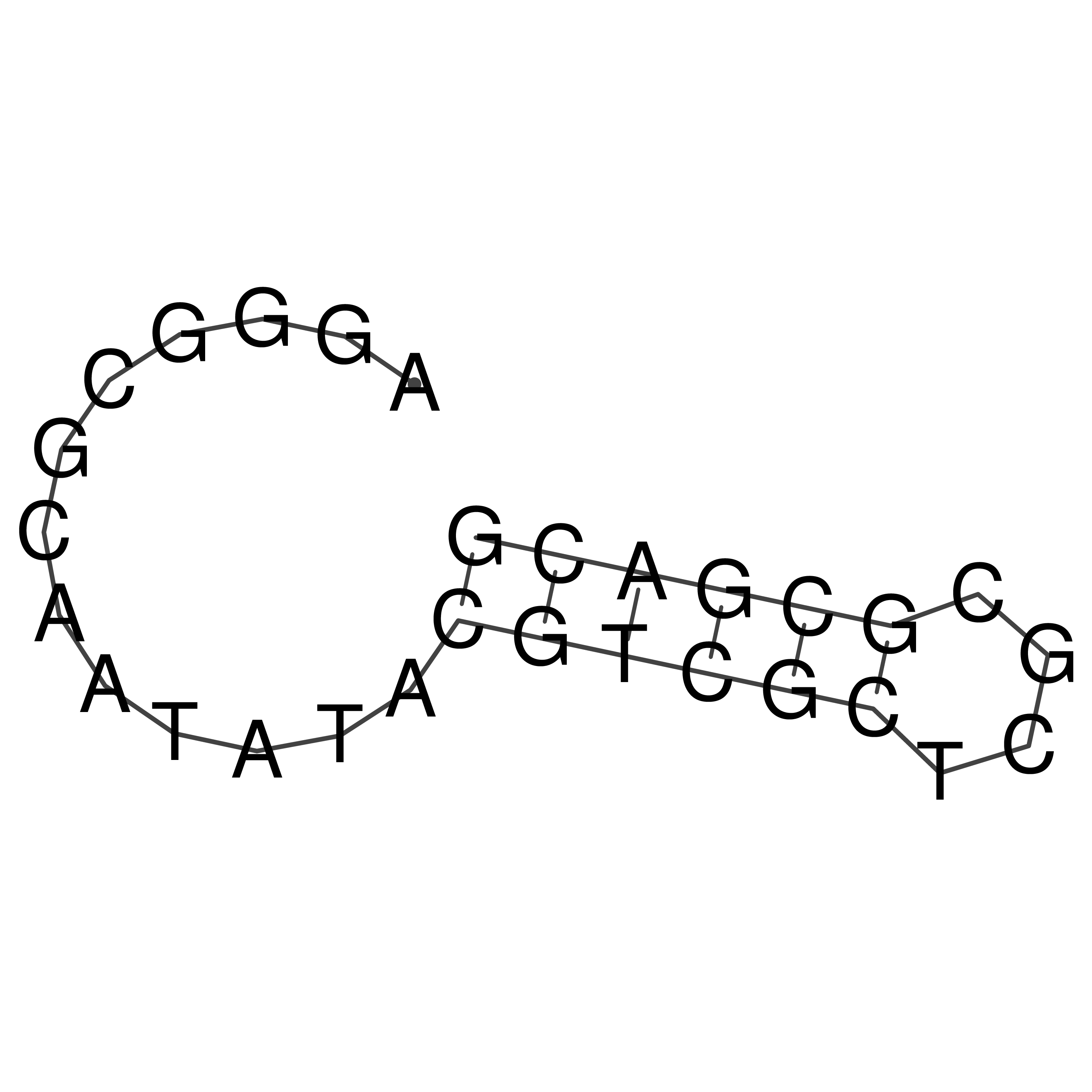
Relaxase
| ID | 9345 | GenBank | WP_142781652 |
| Name | traA_FGF54_RS25170_T29|unnamed2 |
UniProt ID | _ |
| Length | 1547 a.a. | PDB ID | |
| Note | Predicted by oriTfinder 2.0 | ||
Relaxase protein sequence
Download Length: 1547 a.a. Molecular weight: 171184.93 Da Isoelectric Point: 6.6952
>WP_142781652.1 Ti-type conjugative transfer relaxase TraA [Agrobacterium sp. T29]
MAIMFVRAQVIGRGAGRSIVSAAAYRHRARMIDEQVGTSFSYRGSASELVHEELALPDQIPTWLKSAIDG
KSVAGVSQALWNAVDAFETRADAQLARELIIALPGELTRAENIALVREFVADNFTSKGMIADWVFHDKDG
NPHIHLMTTLRPLTEEGFGPKKVPVLGEDGEPLRVVTPDRPNGKIVYTLWAGDKETMKAWKIAWADTANR
HLALAGHEIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGIEMYFAPGDLARRQVMADRLLAEPELLLKQ
LANERSTFDEKDIAKALHRYVDDPVDFANIRARLMASDDLVLLKSQQVDAETGKAAEPAVFTTREILRIE
YDMAQSASVLSKRRGFAVAAEAVAAAIGNVETQNPQKPICLDTEQVDAIRHVTGDKGIAAVVGLAGAGKS
TLLAAARVAWESEGRRVIGAALAGKAAEGLEDSSGIRSRTLASLELAWAGGRDLLERGNVLVIDEAGMIS
SQQMGRVLKVAEDAGAKVVLVGDAMQLQPIQAGAAFRAISDRIGFAELAGVRRQRQEWAREASRLFARGN
VRDGLDAYTQQGRIAEAETRAEIVDRIVADWTDAKRNLIQNTTDEGDAPPLHGDELLVLAHTNEDVKRLN
ESLRKVMMEEGALTGAREFLTARGVREFAAGDRIIFLENARFLEPRARHLGPQYVKNGMLGTVVSTGDKR
GGPLLSVRLDNGRDVVISEDSYRNIDHGYAATIHKSQGATVDRTFVLATGMMDQHLTYVSMTRHRDRADL
YAAREDFEPKLEWERKPRADHAAGVTGELVETGQAKFRPQDEDAKESPYADVKTDDGVVHRLWGVSLPKA
LEDGAVSQGDTVTLRKDGVETVKVEVTVVDEQTREKRTEEREVDRNVWTAELKETAKAREQRIEQESHRP
DLFSQLVERLGRSGAKSTTLDFESEEGYRIHAEDFARRRGIDTFAGITAGMEEGVSKWLAWIADKRAQVA
KLWERASVALGFVIERERHVSYNEGRTETLATEIPTTAKYLIPPTTRFARSVDKDARRAQLASERWKERD
AILRLVLEKIYRDPDSALARLNALASDAANEPRKLADDLAAAPDWLGRLRGSDLMVDGRADHDERNGATT
ALLELLPLARAHATEFRRQAERFGIREEQRRAHMSLSVPMLSKPAMARLVEIEKIREHGGDDAYKIAFAY
AVEDRRLVPEVEAVNDALTARFGWSAFTTKADTVAERNVTERMPEDIAPERREKLFRLFAVVRRFAEEQH
LAEKQDRSKIVAGSSVEVGKETLPMLPMLAAVTEFKMRVEEEARNRAVAVAHYRHHRAALAVTAARIWRD
PAGAVAKIEELVRQGFAGERIAAAISNDPAAYGPLRGSDRIMDRLLAAGRERKEALQTVPEAAACVCPLA
TSWATALDAETQVITEDRQRMAIAIPGLSQAAEEALRTLVADMNKQKKKEDRGKKTRRDFTAGSLPADIK
SEFTAVSRALDERFGSNAILRGDKDAVNRVPPAQRNAFEAMRERLQVLQLTVRIERSQEIVAERQGRAID
QARGLIR
MAIMFVRAQVIGRGAGRSIVSAAAYRHRARMIDEQVGTSFSYRGSASELVHEELALPDQIPTWLKSAIDG
KSVAGVSQALWNAVDAFETRADAQLARELIIALPGELTRAENIALVREFVADNFTSKGMIADWVFHDKDG
NPHIHLMTTLRPLTEEGFGPKKVPVLGEDGEPLRVVTPDRPNGKIVYTLWAGDKETMKAWKIAWADTANR
HLALAGHEIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGIEMYFAPGDLARRQVMADRLLAEPELLLKQ
LANERSTFDEKDIAKALHRYVDDPVDFANIRARLMASDDLVLLKSQQVDAETGKAAEPAVFTTREILRIE
YDMAQSASVLSKRRGFAVAAEAVAAAIGNVETQNPQKPICLDTEQVDAIRHVTGDKGIAAVVGLAGAGKS
TLLAAARVAWESEGRRVIGAALAGKAAEGLEDSSGIRSRTLASLELAWAGGRDLLERGNVLVIDEAGMIS
SQQMGRVLKVAEDAGAKVVLVGDAMQLQPIQAGAAFRAISDRIGFAELAGVRRQRQEWAREASRLFARGN
VRDGLDAYTQQGRIAEAETRAEIVDRIVADWTDAKRNLIQNTTDEGDAPPLHGDELLVLAHTNEDVKRLN
ESLRKVMMEEGALTGAREFLTARGVREFAAGDRIIFLENARFLEPRARHLGPQYVKNGMLGTVVSTGDKR
GGPLLSVRLDNGRDVVISEDSYRNIDHGYAATIHKSQGATVDRTFVLATGMMDQHLTYVSMTRHRDRADL
YAAREDFEPKLEWERKPRADHAAGVTGELVETGQAKFRPQDEDAKESPYADVKTDDGVVHRLWGVSLPKA
LEDGAVSQGDTVTLRKDGVETVKVEVTVVDEQTREKRTEEREVDRNVWTAELKETAKAREQRIEQESHRP
DLFSQLVERLGRSGAKSTTLDFESEEGYRIHAEDFARRRGIDTFAGITAGMEEGVSKWLAWIADKRAQVA
KLWERASVALGFVIERERHVSYNEGRTETLATEIPTTAKYLIPPTTRFARSVDKDARRAQLASERWKERD
AILRLVLEKIYRDPDSALARLNALASDAANEPRKLADDLAAAPDWLGRLRGSDLMVDGRADHDERNGATT
ALLELLPLARAHATEFRRQAERFGIREEQRRAHMSLSVPMLSKPAMARLVEIEKIREHGGDDAYKIAFAY
AVEDRRLVPEVEAVNDALTARFGWSAFTTKADTVAERNVTERMPEDIAPERREKLFRLFAVVRRFAEEQH
LAEKQDRSKIVAGSSVEVGKETLPMLPMLAAVTEFKMRVEEEARNRAVAVAHYRHHRAALAVTAARIWRD
PAGAVAKIEELVRQGFAGERIAAAISNDPAAYGPLRGSDRIMDRLLAAGRERKEALQTVPEAAACVCPLA
TSWATALDAETQVITEDRQRMAIAIPGLSQAAEEALRTLVADMNKQKKKEDRGKKTRRDFTAGSLPADIK
SEFTAVSRALDERFGSNAILRGDKDAVNRVPPAQRNAFEAMRERLQVLQLTVRIERSQEIVAERQGRAID
QARGLIR
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4CP
| ID | 10842 | GenBank | WP_142781649 |
| Name | traG_FGF54_RS25155_T29|unnamed2 |
UniProt ID | _ |
| Length | 639 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 639 a.a. Molecular weight: 70503.40 Da Isoelectric Point: 9.2606
>WP_142781649.1 Ti-type conjugative transfer system protein TraG [Agrobacterium sp. T29]
MALKGKLHPSLLLVFVPIVVTAITVHIVGWRWTGLATGISGKTAYWFLRAAPLPALLLGPLAGLLTVWAL
PMHRRRPIAVVSLLCFLGIVGFYALREYGRLAPSVEHGVVSWDYALSYLDMVAVVGALCGFMAVAASARI
STVVPEQVKRARRATFGDADWLSMSAAGKLFPSDGEIVVGERYRVDKEIVHELPFDPNDRSTWGQGGKAP
LLTYNQDFDSTHVLFFAGSGGYKTTSNVVPTALRYTGPLICLDPSTEVVPMVIEHRSRVLNRDVMVLDPT
NPIMGFNVLDGIETSRQKEEDIVGVAHMLLSESIRFESSTGSYFQSQAHNLLTGLLAHVMLSPDYTGRRN
LRSLRQIVSEPEPSVLAMLRDIQENSGSTFIRETLGVFTNMTEQTFSGVYSTASKDTQWLSLDSYAALVC
GNAFKSSDIVTGKKDVFLNIPASILRSYPGIGRVIIGALINAMTQADGAFKRRALFMLDEVDLLGYMRVL
EEARDRGRKYGISMMLMYQSVGQLERHFGKDGATSWIDGCAFASYAAIKALDTARNVSAQCGEMTVEVKG
SSRNIGWDTKNSASRKSENVNFQRRPLIMPHEITQSMRKDEQIIIVQGHSPIRCGRAIYFRRKEMDAAAR
VNRFVKLGP
MALKGKLHPSLLLVFVPIVVTAITVHIVGWRWTGLATGISGKTAYWFLRAAPLPALLLGPLAGLLTVWAL
PMHRRRPIAVVSLLCFLGIVGFYALREYGRLAPSVEHGVVSWDYALSYLDMVAVVGALCGFMAVAASARI
STVVPEQVKRARRATFGDADWLSMSAAGKLFPSDGEIVVGERYRVDKEIVHELPFDPNDRSTWGQGGKAP
LLTYNQDFDSTHVLFFAGSGGYKTTSNVVPTALRYTGPLICLDPSTEVVPMVIEHRSRVLNRDVMVLDPT
NPIMGFNVLDGIETSRQKEEDIVGVAHMLLSESIRFESSTGSYFQSQAHNLLTGLLAHVMLSPDYTGRRN
LRSLRQIVSEPEPSVLAMLRDIQENSGSTFIRETLGVFTNMTEQTFSGVYSTASKDTQWLSLDSYAALVC
GNAFKSSDIVTGKKDVFLNIPASILRSYPGIGRVIIGALINAMTQADGAFKRRALFMLDEVDLLGYMRVL
EEARDRGRKYGISMMLMYQSVGQLERHFGKDGATSWIDGCAFASYAAIKALDTARNVSAQCGEMTVEVKG
SSRNIGWDTKNSASRKSENVNFQRRPLIMPHEITQSMRKDEQIIIVQGHSPIRCGRAIYFRRKEMDAAAR
VNRFVKLGP
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
| ID | 10843 | GenBank | WP_142781931 |
| Name | tcpA_FGF54_RS26885_T29|unnamed2 |
UniProt ID | _ |
| Length | 1750 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 1750 a.a. Molecular weight: 194623.98 Da Isoelectric Point: 5.4415
>WP_142781931.1 FtsK/SpoIIIE domain-containing protein [Agrobacterium sp. T29]
MDIHELIGKVACSILKEELGDASGEAGTARFLLDGLSIPQTLAVSRSVLADPFLSEAVEIKLPRGLFEGH
ALPDAILTDRNATFYRSADCDKAAFLITNASADEGQAEDMSLHEVTPIGAAQLIERLSAWVLAASAGLAL
TEDAKAWWERSLAGLSQVGSVALERFARYVVATREAVIDEGYPIIEALGYALPALQLPRDPAAFAGIKDK
SRRHASVWKREFIGLRRKRHPYLLKQNPNQIVISETELRDAFEKARDVIPENIHPVVALFIESRPAWNSS
SEALANCLWEHVKPLFEGLAREKTNLGQDTQRFYAEGPEDLLSKEDDEYLELLARRKTTGSPDPEDIEFY
ESHRDEIREDRKLKSSWDKFIYGRPLETEDFLTGLAMVMDTLNARAMVGVERKLTIRCDSLTKRDLRSLN
TEAGLFFSLRYAGLQKLLGAGVQIEFGSLMDYPAVLRGWQDAKDKSAVNRSTAKAAMQLRFQLELETTDF
EGGTSTASAQLIWKYRPDVISSQLTDDWDRLCEHAFVALRCGREPGMAGRRPGSIDLSDVKTLVPAYDRD
RGSLIPTYRRERDLRLLWRANLKTALENNLIDAAASTKISTGFDAFCERYQTAIRSFRVDGASNLLCRDQ
ATSYAELLDLVRLLAPGDRNKDLLLRPLLELGQAPVGDGAAAAIVAPWHPLRLAAIWRKAHLVREVVRKV
IDLPAGLEGDTKLFFRDLSEDMRHVFYPEVVVSWSGHRPELLSLADHQGDYSLHERPVLDGAGGGETNDD
ARAGTNTLLDLTDRYLKLHPHERANMSLVLYNCDSARLPQQLVDGLGDLNDEEDMRCQVMLRHTDGTRLR
DIYRSILTSTSGSAEVLAPSEITQDFMARLRISVIADQAPPPDPRDGRPYDIVFSQDVISRHASVEWYRE
TADPADIATLLPARWSRRRPGAMDDLKSSVYLCSPVQSREGWAFLSAITAFLKEEENLQDGKRLLPVRQL
DFRDDRTARIFEETHDLGAWVVNYDELLDRRQLQNQSVRVIRYKQSATQGRNVVISSRAPLTLLRAMVRR
RLEELQLDLSPSQIDALADRFIGDANDISGDIVLRAAKRGEAAGELIGVVLSRFLARQSLDENRLVGWYF
LDDYASWLGAREETQADILALSPALDADGHLSLRIIVTEAKYVDAVSFASKRKESEKQLRDTMRRIIDAM
AEPDRLDRESWLSRLGDLLLDGIQIPAASNVPLVEWRRRVREGAARIEVVGLSHVFVPTALDGTNITDFS
EVSGAPASRQMIFGRAELKTLITAYIENSKVDRFLTSIDPIYGRVPAPHMPGATVDATAKAAPSPVQTKS
DPVIGDGGHHAEPPTPADEPPIPKSLEPELAGAPSSVRTVDEIVARHLDTSPRQTEADDEWLANTAMMAR
SALQQLGLQAKLIDQKLTPNAAILRFSGSANLTVEQVLKRRSELLTTHRLDIISVRPEPGAIAIYVARNQ
RQVVQIQSLWSRWKPVVSPTGNQDLVVGVREDDNELFVLSPSQRHAPHTLIAGSTGSGKSVLMQSIILGI
AATNDPCHAKIVLIDPKQGVDYFAFDSLPHLEGGIIDQQENAVDQLEHMVLEMDRRYRLFKEARVSNITA
YNAKATPGEVLPTYWIIHDEFAEWMLTDDYRAAVTSTVGRLGVKARAAGIHLIFAAQRPEANVMPMQLRS
QLGNRLILRVDSEGTSEIALGEKGAERLLGKGHMIVRAEGEQGLIYAQVPFASEHFITDVVNSIMLQSVS
MDIHELIGKVACSILKEELGDASGEAGTARFLLDGLSIPQTLAVSRSVLADPFLSEAVEIKLPRGLFEGH
ALPDAILTDRNATFYRSADCDKAAFLITNASADEGQAEDMSLHEVTPIGAAQLIERLSAWVLAASAGLAL
TEDAKAWWERSLAGLSQVGSVALERFARYVVATREAVIDEGYPIIEALGYALPALQLPRDPAAFAGIKDK
SRRHASVWKREFIGLRRKRHPYLLKQNPNQIVISETELRDAFEKARDVIPENIHPVVALFIESRPAWNSS
SEALANCLWEHVKPLFEGLAREKTNLGQDTQRFYAEGPEDLLSKEDDEYLELLARRKTTGSPDPEDIEFY
ESHRDEIREDRKLKSSWDKFIYGRPLETEDFLTGLAMVMDTLNARAMVGVERKLTIRCDSLTKRDLRSLN
TEAGLFFSLRYAGLQKLLGAGVQIEFGSLMDYPAVLRGWQDAKDKSAVNRSTAKAAMQLRFQLELETTDF
EGGTSTASAQLIWKYRPDVISSQLTDDWDRLCEHAFVALRCGREPGMAGRRPGSIDLSDVKTLVPAYDRD
RGSLIPTYRRERDLRLLWRANLKTALENNLIDAAASTKISTGFDAFCERYQTAIRSFRVDGASNLLCRDQ
ATSYAELLDLVRLLAPGDRNKDLLLRPLLELGQAPVGDGAAAAIVAPWHPLRLAAIWRKAHLVREVVRKV
IDLPAGLEGDTKLFFRDLSEDMRHVFYPEVVVSWSGHRPELLSLADHQGDYSLHERPVLDGAGGGETNDD
ARAGTNTLLDLTDRYLKLHPHERANMSLVLYNCDSARLPQQLVDGLGDLNDEEDMRCQVMLRHTDGTRLR
DIYRSILTSTSGSAEVLAPSEITQDFMARLRISVIADQAPPPDPRDGRPYDIVFSQDVISRHASVEWYRE
TADPADIATLLPARWSRRRPGAMDDLKSSVYLCSPVQSREGWAFLSAITAFLKEEENLQDGKRLLPVRQL
DFRDDRTARIFEETHDLGAWVVNYDELLDRRQLQNQSVRVIRYKQSATQGRNVVISSRAPLTLLRAMVRR
RLEELQLDLSPSQIDALADRFIGDANDISGDIVLRAAKRGEAAGELIGVVLSRFLARQSLDENRLVGWYF
LDDYASWLGAREETQADILALSPALDADGHLSLRIIVTEAKYVDAVSFASKRKESEKQLRDTMRRIIDAM
AEPDRLDRESWLSRLGDLLLDGIQIPAASNVPLVEWRRRVREGAARIEVVGLSHVFVPTALDGTNITDFS
EVSGAPASRQMIFGRAELKTLITAYIENSKVDRFLTSIDPIYGRVPAPHMPGATVDATAKAAPSPVQTKS
DPVIGDGGHHAEPPTPADEPPIPKSLEPELAGAPSSVRTVDEIVARHLDTSPRQTEADDEWLANTAMMAR
SALQQLGLQAKLIDQKLTPNAAILRFSGSANLTVEQVLKRRSELLTTHRLDIISVRPEPGAIAIYVARNQ
RQVVQIQSLWSRWKPVVSPTGNQDLVVGVREDDNELFVLSPSQRHAPHTLIAGSTGSGKSVLMQSIILGI
AATNDPCHAKIVLIDPKQGVDYFAFDSLPHLEGGIIDQQENAVDQLEHMVLEMDRRYRLFKEARVSNITA
YNAKATPGEVLPTYWIIHDEFAEWMLTDDYRAAVTSTVGRLGVKARAAGIHLIFAAQRPEANVMPMQLRS
QLGNRLILRVDSEGTSEIALGEKGAERLLGKGHMIVRAEGEQGLIYAQVPFASEHFITDVVNSIMLQSVS
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4SS
T4SS were predicted by using oriTfinder2.
Region 1: 420564..430147
| Locus tag | Coordinates | Strand | Size (bp) | Protein ID | Product | Description |
|---|---|---|---|---|---|---|
| FGF54_RS26950 | 416369..417319 | + | 951 | WP_246667058 | phytanoyl-CoA dioxygenase family protein | - |
| FGF54_RS26955 | 417587..418216 | - | 630 | WP_142781943 | RES family NAD+ phosphorylase | - |
| FGF54_RS26960 | 418213..418998 | - | 786 | WP_142781944 | hypothetical protein | - |
| FGF54_RS26965 | 419573..419923 | - | 351 | WP_080855390 | MarR family transcriptional regulator | - |
| FGF54_RS26970 | 420022..420561 | + | 540 | WP_142781945 | hypothetical protein | - |
| FGF54_RS26975 | 420564..421229 | + | 666 | WP_142781946 | lytic transglycosylase domain-containing protein | virB1 |
| FGF54_RS26980 | 421226..421525 | + | 300 | WP_142781947 | TrbC/VirB2 family protein | virB2 |
| FGF54_RS26985 | 421532..421870 | + | 339 | WP_142781948 | type IV secretion system protein VirB3 | virB3 |
| FGF54_RS26990 | 421863..424229 | + | 2367 | WP_142781949 | VirB4 family type IV secretion/conjugal transfer ATPase | virb4 |
| FGF54_RS26995 | 424226..424927 | + | 702 | WP_142781950 | P-type DNA transfer protein VirB5 | virB5 |
| FGF54_RS27000 | 424924..425157 | + | 234 | WP_142781951 | EexN family lipoprotein | - |
| FGF54_RS27005 | 425161..426093 | + | 933 | WP_142781952 | type IV secretion system protein | virB6 |
| FGF54_RS27010 | 426133..426414 | + | 282 | WP_142781953 | hypothetical protein | - |
| FGF54_RS27015 | 426416..427087 | + | 672 | WP_142781954 | virB8 family protein | virB8 |
| FGF54_RS27020 | 427084..427941 | + | 858 | WP_142781955 | P-type conjugative transfer protein VirB9 | virB9 |
| FGF54_RS27025 | 427950..429125 | + | 1176 | WP_142781956 | type IV secretion system protein VirB10 | virB10 |
| FGF54_RS27030 | 429134..430147 | + | 1014 | WP_142781957 | P-type DNA transfer ATPase VirB11 | virB11 |
| FGF54_RS27035 | 430375..431073 | + | 699 | WP_246667059 | hypothetical protein | - |
| FGF54_RS27040 | 431070..431657 | + | 588 | WP_142781958 | RES family NAD+ phosphorylase | - |
| FGF54_RS27045 | 432192..432452 | + | 261 | WP_142781959 | hypothetical protein | - |
Host bacterium
| ID | 15018 | GenBank | NZ_CP040642 |
| Plasmid name | T29|unnamed2 | Incompatibility group | - |
| Plasmid size | 451191 bp | Coordinate of oriT [Strand] | 16473..16501 [+] |
| Host baterium | Agrobacterium sp. T29 |
Cargo genes
| Drug resistance gene | - |
| Virulence gene | - |
| Metal resistance gene | - |
| Degradation gene | - |
| Symbiosis gene | - |
| Anti-CRISPR | - |