Detailed information of oriT
oriT
The information of the oriT region
| oriTDB ID | 109985 |
| Name | oriT1_pHL21C |
| Organism | Salmonella enterica subsp. enterica strain HL21 |
| Sequence Completeness | - |
| NCBI accession of oriT (coordinates [strand]) | NZ_CP126328 ( 29699..31403 [+], 1705 nt) |
| oriT length | 1705 nt |
| IRs (inverted repeats) | _ |
| Location of nic site | _ |
| Conserved sequence flanking the nic site |
_ |
| Note | Predicted by oriTfinder 2.0 |
oriT sequence
Download Length: 1705 nt
>oriT1_pHL21C
GCCGTATGAATGACATCTATTTCCGTCCAATTCATCGAAACCAGTATTTTGAGGAAATGAAAGCATGATAAAGAAAATTAAAGTAATCATGTTGGCGGCAATAGTTACCGGATGTTCATCGCCACCGCCTCCCGTTCCTGTAGAGTGGGATAAAGCCGCCGCCCCATTAAACACCAGTTTACCGCAATGGAGTGACAATAACGTTATAGTTCCTTCCCCGACAGTTAACGGTAAATGGACATCATCAATCAGCGCACAAAGTTTCTACGATACAATATGGACTCCAGCAGTATTTTACGCAGTCGCCCACTCAACACGAACTGTCGTCACTGCACAATCCGGCACTGATTTCTTTAATGCCAAAAACTGGCTTCGCCAGAATGGCGCAAAAGGTGTTATTGAATACCAGCCTGTCTTTAATTGTCTGACGTGCAGAGAAACCACTATTTATTTCTCTCGCTAATCCATTTAAGCAACACAATCTAATAAGGATTTACCATGAAAAAAACCGTTATCGCGGCGGCTGTATTATGCCTGACCGCAGGAATGCCGATTTATTCATTTGCTGCTGACCCGTGCGAAGTTGTTCTTTGCATGTACGGAAAAGCCACGGGTAATAGTGGCGGGAGTGAATGCAGTTCAGCAGAACGTGCATTTTTTAAAATCAACGCATTTAAAAAACACCATCGTTTTAATCCGGGTAAAACATTCGATATGCGAAAAGAATTTTTAGGCAAATGTAAAGCCGCAGCCCCTGAATCAATAAGCAAAATCCTTTCAAAATTTGGCAGAGTGAAAGGATAACTGACATATCCATTTTGATATGAGAGGTTCGAAATGATAAACGAAGATTTATTCATTAAGAATATACACTCAAAGAATCAGGACAGAATATCTGTAGCCCTGGTATATGACACGTTATCAAAAGAAGCCCACAGAGGTTGTGGGCTGTATTACGAAATATACGAAAGCTGTTTTATCGGTCTTTTGCGCGATCATCTTTCAGAACTTAATGAAGCTGACGCAAATAAATTAAGACGCTATGCCGAGAGTAAAGGTACGAAAATTGATGATGCGTCCTACAGTGAAGCACTGGAAGCTGAAAGGGAGTGCAGGGCTGAAATATACCGCGAGCAAATGTAATCACACCAAACAAAGGTGTATTGTACAATACACAGACTAACAGGCGACGGGACTTTAAGGCTTCATTATTTTTGGCTTCAATTTCGAAGAAATTGTTAAGACGAAAAATAATGAAGTGGTACGCGGAAAGAAAATTCAATTTCGAAGAAATTGCTAATTTTCAGGAACCGCGCCCACCTGCGAACATTCGCCCACAGCGAATTGAGCAGGCCGGGGGAGCCGCAAAAATTTTGCCGCCCCAGCGAGCAAAAAGGCACGCCCACGTGCCGTTTTTTGTGGGGGGCTTGCCCCGCACACCGTCGCAGCCAGGTAATATAACCCGCCCCAGCGGGGGATATTACCGATTAGGCGCGACCAACCCCTTTAAAGCAGCGTTCCGATTTTTTTGAGCTTGCGAGGAAAAATAGGCTAAACGCAGCGTCTTAAAGGGGTTGGTCGCGCGTAGCGCAAGACGGTGTGCCGCCTTTGACCTTGGGGGTTTTGGCTCGGCGTCCAGCCGGGACATTACCCCCATGTGTCATGCAGTGAGGGCGTCCAGCCCGAACGTAATGGCACACGCCGT
GCCGTATGAATGACATCTATTTCCGTCCAATTCATCGAAACCAGTATTTTGAGGAAATGAAAGCATGATAAAGAAAATTAAAGTAATCATGTTGGCGGCAATAGTTACCGGATGTTCATCGCCACCGCCTCCCGTTCCTGTAGAGTGGGATAAAGCCGCCGCCCCATTAAACACCAGTTTACCGCAATGGAGTGACAATAACGTTATAGTTCCTTCCCCGACAGTTAACGGTAAATGGACATCATCAATCAGCGCACAAAGTTTCTACGATACAATATGGACTCCAGCAGTATTTTACGCAGTCGCCCACTCAACACGAACTGTCGTCACTGCACAATCCGGCACTGATTTCTTTAATGCCAAAAACTGGCTTCGCCAGAATGGCGCAAAAGGTGTTATTGAATACCAGCCTGTCTTTAATTGTCTGACGTGCAGAGAAACCACTATTTATTTCTCTCGCTAATCCATTTAAGCAACACAATCTAATAAGGATTTACCATGAAAAAAACCGTTATCGCGGCGGCTGTATTATGCCTGACCGCAGGAATGCCGATTTATTCATTTGCTGCTGACCCGTGCGAAGTTGTTCTTTGCATGTACGGAAAAGCCACGGGTAATAGTGGCGGGAGTGAATGCAGTTCAGCAGAACGTGCATTTTTTAAAATCAACGCATTTAAAAAACACCATCGTTTTAATCCGGGTAAAACATTCGATATGCGAAAAGAATTTTTAGGCAAATGTAAAGCCGCAGCCCCTGAATCAATAAGCAAAATCCTTTCAAAATTTGGCAGAGTGAAAGGATAACTGACATATCCATTTTGATATGAGAGGTTCGAAATGATAAACGAAGATTTATTCATTAAGAATATACACTCAAAGAATCAGGACAGAATATCTGTAGCCCTGGTATATGACACGTTATCAAAAGAAGCCCACAGAGGTTGTGGGCTGTATTACGAAATATACGAAAGCTGTTTTATCGGTCTTTTGCGCGATCATCTTTCAGAACTTAATGAAGCTGACGCAAATAAATTAAGACGCTATGCCGAGAGTAAAGGTACGAAAATTGATGATGCGTCCTACAGTGAAGCACTGGAAGCTGAAAGGGAGTGCAGGGCTGAAATATACCGCGAGCAAATGTAATCACACCAAACAAAGGTGTATTGTACAATACACAGACTAACAGGCGACGGGACTTTAAGGCTTCATTATTTTTGGCTTCAATTTCGAAGAAATTGTTAAGACGAAAAATAATGAAGTGGTACGCGGAAAGAAAATTCAATTTCGAAGAAATTGCTAATTTTCAGGAACCGCGCCCACCTGCGAACATTCGCCCACAGCGAATTGAGCAGGCCGGGGGAGCCGCAAAAATTTTGCCGCCCCAGCGAGCAAAAAGGCACGCCCACGTGCCGTTTTTTGTGGGGGGCTTGCCCCGCACACCGTCGCAGCCAGGTAATATAACCCGCCCCAGCGGGGGATATTACCGATTAGGCGCGACCAACCCCTTTAAAGCAGCGTTCCGATTTTTTTGAGCTTGCGAGGAAAAATAGGCTAAACGCAGCGTCTTAAAGGGGTTGGTCGCGCGTAGCGCAAGACGGTGTGCCGCCTTTGACCTTGGGGGTTTTGGCTCGGCGTCCAGCCGGGACATTACCCCCATGTGTCATGCAGTGAGGGCGTCCAGCCCGAACGTAATGGCACACGCCGT
Visualization of oriT structure
oriT secondary structure
Predicted by RNAfold.
Download structure file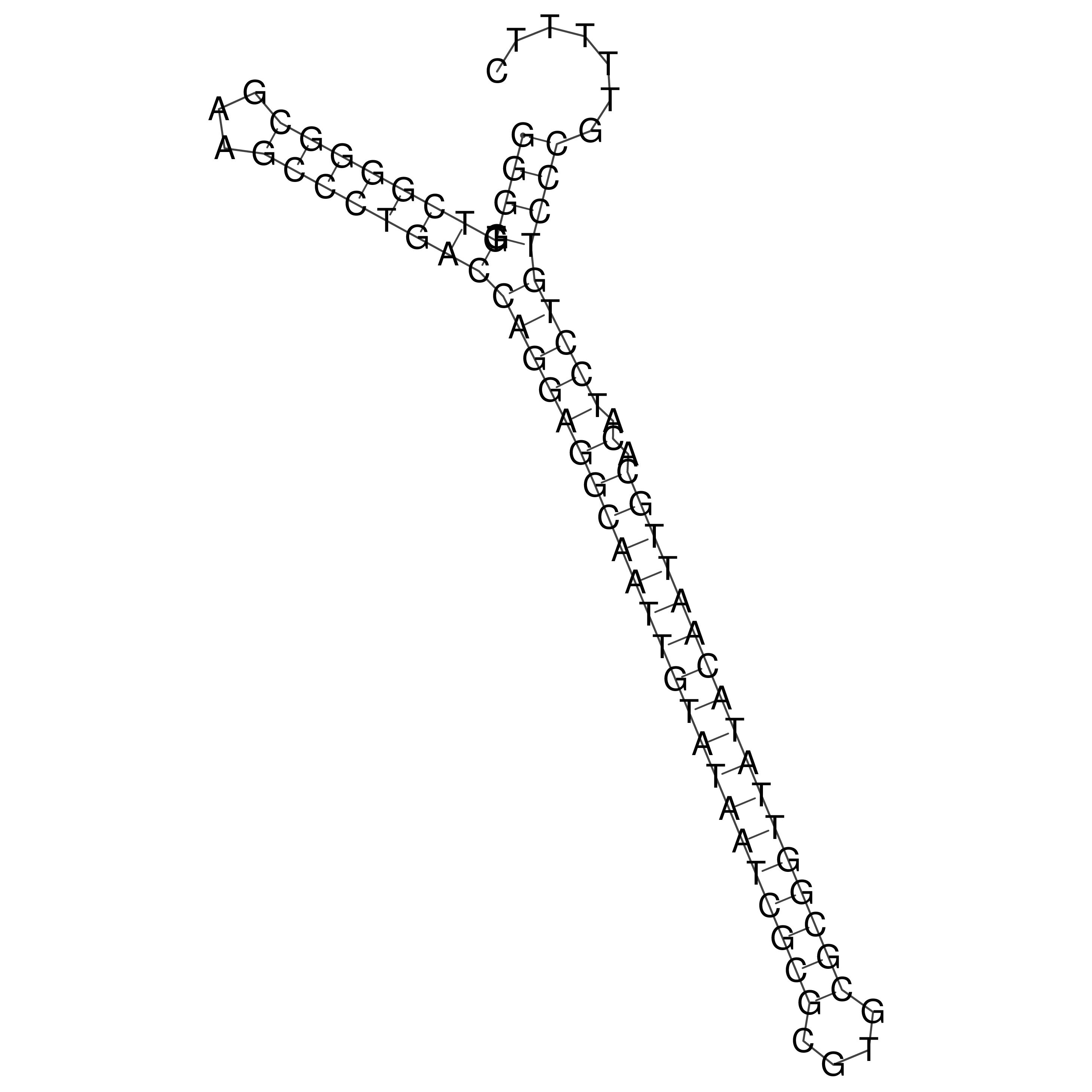
T4CP
| ID | 7281 | GenBank | WP_284546350 |
| Name | t4cp2_QN088_RS24455_pHL21C |
UniProt ID | _ |
| Length | 578 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 578 a.a. Molecular weight: 65626.88 Da Isoelectric Point: 7.4566
>WP_284546350.1 type IV secretion system DNA-binding domain-containing protein [Salmonella enterica]
MGSHLMQRLNAFADAFSFFLLWLQNSPVILSLLAGLTLPFIFHLPREERKNAPFWLKSVACVSIFFFIFG
TISPLTIQGLSYFFKSLDNNILFRVPLWIMTIIFTAAGLIFHIAARRLLAGEIDNLKHRMIKKSKLERNT
RTDVRKVKELLPDSIEYNPLDYIDLKKGVFIGLNKDDQPQYITIKEFKTQHAAIIGTTGSGKGVTATVLL
YQAILLGEAVFVEDPKDDEWAPHVLREACKKAGKKFTLINLNKLNFQLDLLADISHEQLEELFNAGFSLA
KKGEASDFYRIADRRAARNTSAIYEKGMTLRDLFNTDFVQSLREDVPAFCGELEEIALVNSINATKGFSL
KEVFDEGGCCYIIGSTRNQKIISAQRMILTRLIQIAETRDRINSTPRTVAIFLDELKYHLSRPALEGLGT
ARDKGVHIFMAFQAIDDLRDCPSDLNGDSVIGAIIENAKFKLIYKIQNPETAEWAAKMTGSILVDDEMRK
VRTDLSLTEKVDTDRMIRQAESYYVDSNMFLNLPEKVGFVFTSTELPRATKMFQVQVKKENIELLSFEYK
QATPEKNESQEHKPSINL
MGSHLMQRLNAFADAFSFFLLWLQNSPVILSLLAGLTLPFIFHLPREERKNAPFWLKSVACVSIFFFIFG
TISPLTIQGLSYFFKSLDNNILFRVPLWIMTIIFTAAGLIFHIAARRLLAGEIDNLKHRMIKKSKLERNT
RTDVRKVKELLPDSIEYNPLDYIDLKKGVFIGLNKDDQPQYITIKEFKTQHAAIIGTTGSGKGVTATVLL
YQAILLGEAVFVEDPKDDEWAPHVLREACKKAGKKFTLINLNKLNFQLDLLADISHEQLEELFNAGFSLA
KKGEASDFYRIADRRAARNTSAIYEKGMTLRDLFNTDFVQSLREDVPAFCGELEEIALVNSINATKGFSL
KEVFDEGGCCYIIGSTRNQKIISAQRMILTRLIQIAETRDRINSTPRTVAIFLDELKYHLSRPALEGLGT
ARDKGVHIFMAFQAIDDLRDCPSDLNGDSVIGAIIENAKFKLIYKIQNPETAEWAAKMTGSILVDDEMRK
VRTDLSLTEKVDTDRMIRQAESYYVDSNMFLNLPEKVGFVFTSTELPRATKMFQVQVKKENIELLSFEYK
QATPEKNESQEHKPSINL
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
| ID | 7282 | GenBank | WP_284546350 |
| Name | t4cp2_QN088_RS24605_pHL21C |
UniProt ID | _ |
| Length | 578 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 578 a.a. Molecular weight: 65626.88 Da Isoelectric Point: 7.4566
>WP_284546350.1 type IV secretion system DNA-binding domain-containing protein [Salmonella enterica]
MGSHLMQRLNAFADAFSFFLLWLQNSPVILSLLAGLTLPFIFHLPREERKNAPFWLKSVACVSIFFFIFG
TISPLTIQGLSYFFKSLDNNILFRVPLWIMTIIFTAAGLIFHIAARRLLAGEIDNLKHRMIKKSKLERNT
RTDVRKVKELLPDSIEYNPLDYIDLKKGVFIGLNKDDQPQYITIKEFKTQHAAIIGTTGSGKGVTATVLL
YQAILLGEAVFVEDPKDDEWAPHVLREACKKAGKKFTLINLNKLNFQLDLLADISHEQLEELFNAGFSLA
KKGEASDFYRIADRRAARNTSAIYEKGMTLRDLFNTDFVQSLREDVPAFCGELEEIALVNSINATKGFSL
KEVFDEGGCCYIIGSTRNQKIISAQRMILTRLIQIAETRDRINSTPRTVAIFLDELKYHLSRPALEGLGT
ARDKGVHIFMAFQAIDDLRDCPSDLNGDSVIGAIIENAKFKLIYKIQNPETAEWAAKMTGSILVDDEMRK
VRTDLSLTEKVDTDRMIRQAESYYVDSNMFLNLPEKVGFVFTSTELPRATKMFQVQVKKENIELLSFEYK
QATPEKNESQEHKPSINL
MGSHLMQRLNAFADAFSFFLLWLQNSPVILSLLAGLTLPFIFHLPREERKNAPFWLKSVACVSIFFFIFG
TISPLTIQGLSYFFKSLDNNILFRVPLWIMTIIFTAAGLIFHIAARRLLAGEIDNLKHRMIKKSKLERNT
RTDVRKVKELLPDSIEYNPLDYIDLKKGVFIGLNKDDQPQYITIKEFKTQHAAIIGTTGSGKGVTATVLL
YQAILLGEAVFVEDPKDDEWAPHVLREACKKAGKKFTLINLNKLNFQLDLLADISHEQLEELFNAGFSLA
KKGEASDFYRIADRRAARNTSAIYEKGMTLRDLFNTDFVQSLREDVPAFCGELEEIALVNSINATKGFSL
KEVFDEGGCCYIIGSTRNQKIISAQRMILTRLIQIAETRDRINSTPRTVAIFLDELKYHLSRPALEGLGT
ARDKGVHIFMAFQAIDDLRDCPSDLNGDSVIGAIIENAKFKLIYKIQNPETAEWAAKMTGSILVDDEMRK
VRTDLSLTEKVDTDRMIRQAESYYVDSNMFLNLPEKVGFVFTSTELPRATKMFQVQVKKENIELLSFEYK
QATPEKNESQEHKPSINL
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
| ID | 7283 | GenBank | WP_284546357 |
| Name | t4cp2_QN088_RS24700_pHL21C |
UniProt ID | _ |
| Length | 912 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 912 a.a. Molecular weight: 103348.32 Da Isoelectric Point: 7.4787
>WP_284546357.1 VirB3 family type IV secretion system protein [Salmonella enterica]
MAKLLKAMKRPAALWGVPMVPLLAVTGVTIIVAIWTSVALLFLLPVQFLVMKSLTRNEPMRFNLIAVWLR
AKGKPVANRLFGATTFMPVEHDDVDIKEFLDAMKLNQCATIKKYIPYSSHIHQHVVRSPKSDLYCTWELM
GTPFDCESDETLQFGTNQLHGLIRSFEGMPVTFYIHNDRNTFTDNLHQDSGNPYADEVSRLYYASVGSFR
RNRLFLTVCYRPFVSLEKAERKRMKDSQKLKELDGALLEMLEIKSTLDTALARYGAHSLGTFTEGKMVFS
SQLAFYEYLLTHQWRKVRVTRTPAYDVMGAAALFFSAESGQINHANGTQYFRGLEIKEFSEETATGMMDS
LLYAPCDYVITQSYTCMSREEAKKTIKRTRRLLMSADDDAVSQRLDLDVALDLLTSGKIAYGKHHFSIMV
YSPSLESLVADTNEISNALNNIGITPVPAEISLSAAYMAQLPGNYNLRPRKGELSSQNFVELAALHNFYP
GKRDKAPWGYAMALMRTPSGDGYYINLHNTLADKDEFNEKNPASTCILGTNGSGKTMLMTFFEIMQQKYS
REDSFSPDAKTKRLTTVYLDKDRGAEMNIRALGGRYYRVISGESTGWNPFSLPATKRNINFIKQLMKILC
TRNGATITPRDERRLNDAVNAVMSDEPEYRRFGITRLREQLPEPATKEAQENGLDIRLSQWAQGGEFGWV
FDNESDTFDISNCDNFGIDGTEFLDDASVCAPISFYLLYRITSLLDGRRLVIFMDEFWKWLRDPVFKDFA
YNKLKTIRKLNGMLVVGTQSPAEIIKDDIAPAVIEQCGTQILAANPNADRAHYVDGMKFEPEVFDVVKGL
DPQARQYVVVKNQFKRGDTKRFAARVTLDLSGIGRYTKVMSGDAPNLEIFESIYREGMQPHEWLDTYLAK
AL
MAKLLKAMKRPAALWGVPMVPLLAVTGVTIIVAIWTSVALLFLLPVQFLVMKSLTRNEPMRFNLIAVWLR
AKGKPVANRLFGATTFMPVEHDDVDIKEFLDAMKLNQCATIKKYIPYSSHIHQHVVRSPKSDLYCTWELM
GTPFDCESDETLQFGTNQLHGLIRSFEGMPVTFYIHNDRNTFTDNLHQDSGNPYADEVSRLYYASVGSFR
RNRLFLTVCYRPFVSLEKAERKRMKDSQKLKELDGALLEMLEIKSTLDTALARYGAHSLGTFTEGKMVFS
SQLAFYEYLLTHQWRKVRVTRTPAYDVMGAAALFFSAESGQINHANGTQYFRGLEIKEFSEETATGMMDS
LLYAPCDYVITQSYTCMSREEAKKTIKRTRRLLMSADDDAVSQRLDLDVALDLLTSGKIAYGKHHFSIMV
YSPSLESLVADTNEISNALNNIGITPVPAEISLSAAYMAQLPGNYNLRPRKGELSSQNFVELAALHNFYP
GKRDKAPWGYAMALMRTPSGDGYYINLHNTLADKDEFNEKNPASTCILGTNGSGKTMLMTFFEIMQQKYS
REDSFSPDAKTKRLTTVYLDKDRGAEMNIRALGGRYYRVISGESTGWNPFSLPATKRNINFIKQLMKILC
TRNGATITPRDERRLNDAVNAVMSDEPEYRRFGITRLREQLPEPATKEAQENGLDIRLSQWAQGGEFGWV
FDNESDTFDISNCDNFGIDGTEFLDDASVCAPISFYLLYRITSLLDGRRLVIFMDEFWKWLRDPVFKDFA
YNKLKTIRKLNGMLVVGTQSPAEIIKDDIAPAVIEQCGTQILAANPNADRAHYVDGMKFEPEVFDVVKGL
DPQARQYVVVKNQFKRGDTKRFAARVTLDLSGIGRYTKVMSGDAPNLEIFESIYREGMQPHEWLDTYLAK
AL
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4SS
T4SS were predicted by using oriTfinder2.
Region 1: 19828..33356
| Locus tag | Coordinates | Strand | Size (bp) | Protein ID | Product | Description |
|---|---|---|---|---|---|---|
| QN088_RS24515 (QN088_24515) | 16970..17677 | - | 708 | WP_268866177 | RepA protein | - |
| QN088_RS24520 (QN088_24520) | 18137..18496 | - | 360 | WP_034950652 | helix-turn-helix transcriptional regulator | - |
| QN088_RS24525 (QN088_24525) | 18745..19200 | + | 456 | WP_284546355 | transcription termination/antitermination NusG family protein | - |
| QN088_RS24530 (QN088_24530) | 19272..19487 | + | 216 | WP_004178170 | hypothetical protein | - |
| QN088_RS24535 (QN088_24535) | 19492..19710 | + | 219 | WP_004178172 | hypothetical protein | - |
| QN088_RS24540 (QN088_24540) | 19828..20538 | + | 711 | WP_284546356 | lytic transglycosylase domain-containing protein | virB1 |
| QN088_RS24545 (QN088_24545) | 20535..20840 | + | 306 | WP_012457109 | TrbC/VirB2 family protein | virB2 |
| QN088_RS24550 (QN088_24550) | 20853..23589 | + | 2737 | Protein_28 | VirB3 family type IV secretion system protein | - |
| QN088_RS24555 (QN088_24555) | 23607..24308 | + | 702 | WP_284546359 | type IV secretion system protein | - |
| QN088_RS24560 (QN088_24560) | 24320..24544 | + | 225 | WP_053271848 | EexN family lipoprotein | - |
| QN088_RS24565 (QN088_24565) | 24556..25632 | + | 1077 | WP_284546347 | type IV secretion system protein | virB6 |
| QN088_RS24570 (QN088_24570) | 25848..26531 | + | 684 | WP_109176809 | type IV secretion system protein | virB8 |
| QN088_RS24575 (QN088_24575) | 26528..27436 | + | 909 | WP_284546193 | P-type conjugative transfer protein VirB9 | virB9 |
| QN088_RS24580 (QN088_24580) | 27483..28751 | + | 1269 | WP_284546348 | VirB10/TraB/TrbI family type IV secretion system protein | virB10 |
| QN088_RS24585 (QN088_24585) | 28741..29766 | + | 1026 | WP_284546192 | P-type DNA transfer ATPase VirB11 | virB11 |
| QN088_RS24590 (QN088_24590) | 29763..30161 | + | 399 | WP_284546191 | cag pathogenicity island Cag12 family protein | - |
| QN088_RS24595 (QN088_24595) | 30197..30502 | + | 306 | WP_284546349 | conjugal transfer protein | - |
| QN088_RS24600 (QN088_24600) | 30536..30841 | + | 306 | WP_032152569 | hypothetical protein | - |
| QN088_RS24605 (QN088_24605) | 31620..33356 | + | 1737 | WP_284546350 | type IV secretion system DNA-binding domain-containing protein | virb4 |
| QN088_RS24610 (QN088_24610) | 33365..34119 | + | 755 | Protein_40 | MobC family replication-relaxation protein | - |
| QN088_RS24615 (QN088_24615) | 34156..34629 | + | 474 | WP_284546351 | thermonuclease family protein | - |
| QN088_RS24620 (QN088_24620) | 34690..35031 | + | 342 | WP_350030269 | hypothetical protein | - |
| QN088_RS24625 (QN088_24625) | 35068..35301 | - | 234 | WP_004178129 | hypothetical protein | - |
| QN088_RS24630 (QN088_24630) | 35342..35896 | - | 555 | WP_284546353 | chromosome partitioning protein | - |
| QN088_RS24635 (QN088_24635) | 36106..36888 | - | 783 | WP_284546354 | SprT-like domain-containing protein | - |
| QN088_RS24640 (QN088_24640) | 37323..37601 | + | 279 | WP_058216745 | type II toxin-antitoxin system HicA family toxin | - |
| QN088_RS24645 (QN088_24645) | 37594..37941 | + | 348 | WP_058216744 | type II toxin-antitoxin system HicB family antitoxin | - |
| QN088_RS24650 (QN088_24650) | 38018..38200 | - | 183 | WP_284546360 | colicin release lysis protein | - |
Host bacterium
| ID | 10420 | GenBank | NZ_CP126328 |
| Plasmid name | pHL21C | Incompatibility group | - |
| Plasmid size | 48318 bp | Coordinate of oriT [Strand] | 5542..7246 [+]; 29699..31403 [+] |
| Host baterium | Salmonella enterica subsp. enterica strain HL21 |
Cargo genes
| Drug resistance gene | - |
| Virulence gene | - |
| Metal resistance gene | - |
| Degradation gene | - |
| Symbiosis gene | - |
| Anti-CRISPR | - |