Detailed information of oriT
oriT
The information of the oriT region
| oriTDB ID | 107595 |
| Name | oriT_pRheCIAT894c |
| Organism | Rhizobium sp. CIAT894 |
| Sequence Completeness | - |
| NCBI accession of oriT (coordinates [strand]) | NZ_CP020950 (229850..229878 [+], 29 nt) |
| oriT length | 29 nt |
| IRs (inverted repeats) | 14..19, 24..29 (CGTCGC..GCGACG) |
| Location of nic site | _ |
| Conserved sequence flanking the nic site |
_ |
| Note | Predicted by oriTfinder 2.0 |
oriT sequence
Download Length: 29 nt
>oriT_pRheCIAT894c
AGGGCGCAATATACGTCGCTGTCGCGACG
AGGGCGCAATATACGTCGCTGTCGCGACG
Visualization of oriT structure
oriT secondary structure
Predicted by RNAfold.
Download structure file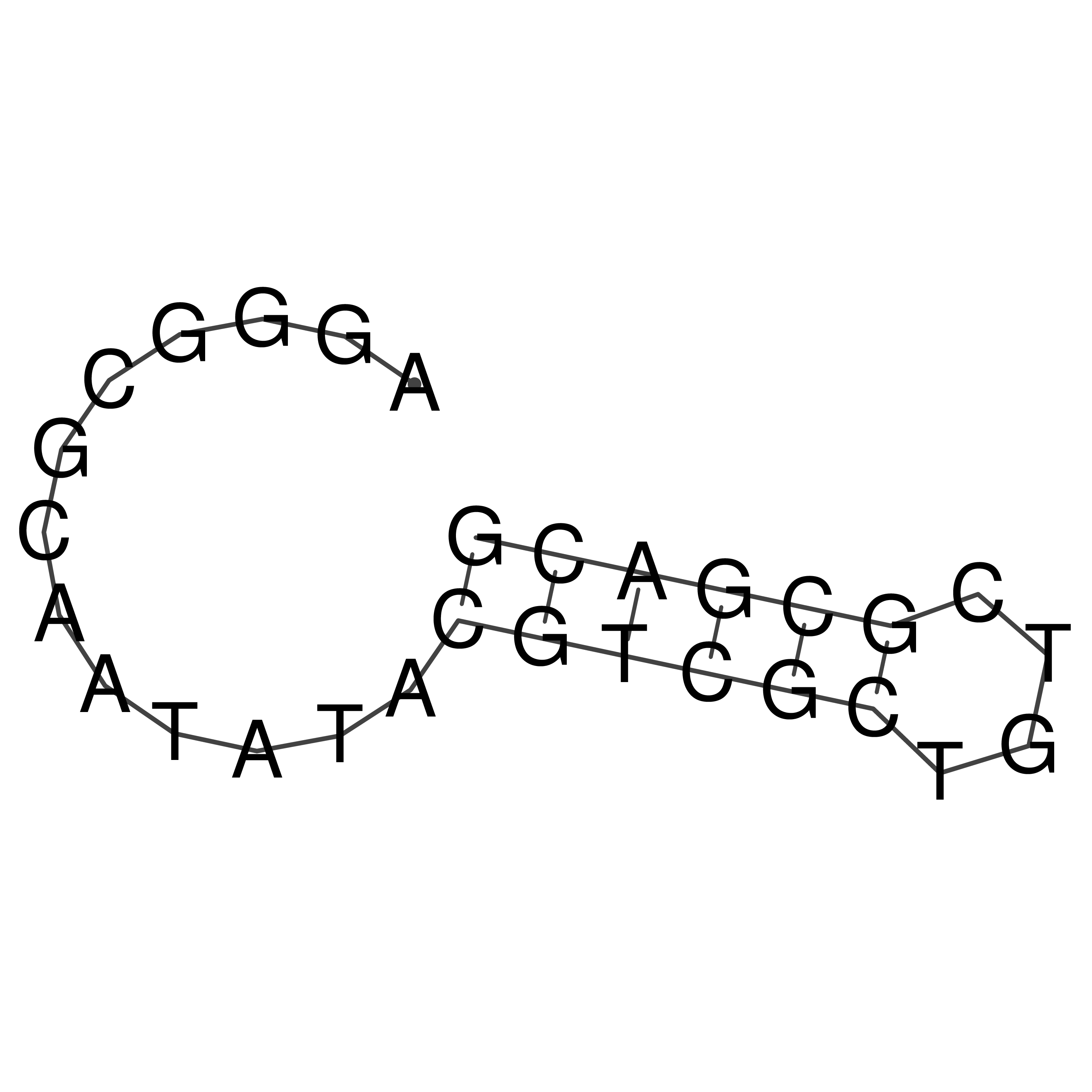
Relaxase
| ID | 5105 | GenBank | WP_071088540 |
| Name | traA_RHEC894_RS25135_pRheCIAT894c |
UniProt ID | A0A437N6N5 |
| Length | 1558 a.a. | PDB ID | |
| Note | Predicted by oriTfinder 2.0 | ||
Relaxase protein sequence
Download Length: 1558 a.a. Molecular weight: 172057.27 Da Isoelectric Point: 7.2379
>WP_071088540.1 MULTISPECIES: Ti-type conjugative transfer relaxase TraA [unclassified Rhizobium]
MAIMFVRAQVISRGSGRSIVSAAAYRHRARMMDEQAGTSFSYRGGAGELMYEELALPDEIPDWLRSAISG
QSVSKASEVFWNAVDAFETRADAQLARELIIALPEELTRAENITLVREFVRDNLTSKGMIADWVYHDKDG
NPHIHLMTTLRPATEEGFGAKKVPVLGEGGKPLRVVTPDRPNGKIVYKVWAGDKETMRAWKIAWAETANR
HLALAGHDIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGRELHFAPADLARRQEMADRLLSEPELLLKQ
LGNERSTFDERDIARALHRYVDDPTDFANIRARLMASDQLVILKPQEIEAETGKVSEPAVFTTREMLRIE
YDMAQSARVLSERRGFGVSERNVTVAIERVESGDPKNPFRLDAEQVDAVRHVTGDGGIAAIVGLAGAGKS
TLLAAARLAWESEGHRVIGAALAGKAAEGLQDSSGIKSRTLASWELAWGNGRDTLHRGDVLVIDEAGMVA
SQQMARVLKIAEEAEVKVVLVGDAMQLQPIQAGAAFRAITERIGFAELVGVRRQREAWARNASRLFARGE
VEKGLDAYARHGHLVEAGSREETIDRIVSDWAAARREAIERSTSEGGDGRLRGDELLVLAHTNDDVRKLN
EALRSVMTQEGALSESRSFRSERGVREFAAGDRIIFLENARFLEPRAKHSGPQYVKNGMLGTVVSTGDKR
GDPLLSVLLDNGRKLVFSEDSYRHVDHGYAATIHKSQGATVDRTFVLATGMMDQHLTYVSMTRHRDRVDL
YAAKEDFAAKPEWGRKPRVDHATGVTGELVETGEAKFRPDDEDADDSPYADVRADDGTVHRLWGVSLPKA
LEEAGIQEGDTVTLRKDGVERVKVQIAVVDEKTGHKHYEEREVDRNVWTASQVETASARQERIERESHRP
ELFNPLVERLSRSGAKTTTLDFESEASYRAHANDFARRRGLDHLSLAAAEMEQSLTRRWAWIAAKREQVE
KLWERASVALGFAIERERRVAYNEERSQTMVEATSSDARTASHSVSGASAAETRYLIPPATSFVSSVEED
ARLAQLASPAWTEREVILRPLLQKIYRDPDAALVSLNALASDIGVAPRRLADDLAAAPGRLGRLRGSELI
VDGRAAREERNLAVAAVKELLPMARAHATEFRRNAERFELREQTRRAHMSLSIPALSERAMARLMEIEAV
RSQGGDDAYKTAFALAAKDRSVVREIKAVSEALTARFGWSAFSAKADAIAERNIVERMPEDLTDEWRGKL
TRLFDAVRRFADEQHLAERRDRSKVVAGASADLSKEPGTEKIIMPPMFAAVTEFKVPIDDEARSRALASP
VYRQQRAALANAATTIWRDPAEVVGKIEELLQKGFAAERIGAAVTNNPAAYGALRGSDRLMDRMLTSGRE
RKEAVAAVPEAAARLRALGAAHLNALDAQRQAITDERRRMAVAIPALSKAAEEALAHLTVEVSKDSRKLS
VSAASLDPGIGREFAAVSRALDERFGRNALVRGDKDIANVVPPAQRGAFAAMQERLKVLQQTVRLQSSEQ
IIVERRQQTANRSRGINL
MAIMFVRAQVISRGSGRSIVSAAAYRHRARMMDEQAGTSFSYRGGAGELMYEELALPDEIPDWLRSAISG
QSVSKASEVFWNAVDAFETRADAQLARELIIALPEELTRAENITLVREFVRDNLTSKGMIADWVYHDKDG
NPHIHLMTTLRPATEEGFGAKKVPVLGEGGKPLRVVTPDRPNGKIVYKVWAGDKETMRAWKIAWAETANR
HLALAGHDIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGRELHFAPADLARRQEMADRLLSEPELLLKQ
LGNERSTFDERDIARALHRYVDDPTDFANIRARLMASDQLVILKPQEIEAETGKVSEPAVFTTREMLRIE
YDMAQSARVLSERRGFGVSERNVTVAIERVESGDPKNPFRLDAEQVDAVRHVTGDGGIAAIVGLAGAGKS
TLLAAARLAWESEGHRVIGAALAGKAAEGLQDSSGIKSRTLASWELAWGNGRDTLHRGDVLVIDEAGMVA
SQQMARVLKIAEEAEVKVVLVGDAMQLQPIQAGAAFRAITERIGFAELVGVRRQREAWARNASRLFARGE
VEKGLDAYARHGHLVEAGSREETIDRIVSDWAAARREAIERSTSEGGDGRLRGDELLVLAHTNDDVRKLN
EALRSVMTQEGALSESRSFRSERGVREFAAGDRIIFLENARFLEPRAKHSGPQYVKNGMLGTVVSTGDKR
GDPLLSVLLDNGRKLVFSEDSYRHVDHGYAATIHKSQGATVDRTFVLATGMMDQHLTYVSMTRHRDRVDL
YAAKEDFAAKPEWGRKPRVDHATGVTGELVETGEAKFRPDDEDADDSPYADVRADDGTVHRLWGVSLPKA
LEEAGIQEGDTVTLRKDGVERVKVQIAVVDEKTGHKHYEEREVDRNVWTASQVETASARQERIERESHRP
ELFNPLVERLSRSGAKTTTLDFESEASYRAHANDFARRRGLDHLSLAAAEMEQSLTRRWAWIAAKREQVE
KLWERASVALGFAIERERRVAYNEERSQTMVEATSSDARTASHSVSGASAAETRYLIPPATSFVSSVEED
ARLAQLASPAWTEREVILRPLLQKIYRDPDAALVSLNALASDIGVAPRRLADDLAAAPGRLGRLRGSELI
VDGRAAREERNLAVAAVKELLPMARAHATEFRRNAERFELREQTRRAHMSLSIPALSERAMARLMEIEAV
RSQGGDDAYKTAFALAAKDRSVVREIKAVSEALTARFGWSAFSAKADAIAERNIVERMPEDLTDEWRGKL
TRLFDAVRRFADEQHLAERRDRSKVVAGASADLSKEPGTEKIIMPPMFAAVTEFKVPIDDEARSRALASP
VYRQQRAALANAATTIWRDPAEVVGKIEELLQKGFAAERIGAAVTNNPAAYGALRGSDRLMDRMLTSGRE
RKEAVAAVPEAAARLRALGAAHLNALDAQRQAITDERRRMAVAIPALSKAAEEALAHLTVEVSKDSRKLS
VSAASLDPGIGREFAAVSRALDERFGRNALVRGDKDIANVVPPAQRGAFAAMQERLKVLQQTVRLQSSEQ
IIVERRQQTANRSRGINL
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4CP
| ID | 5327 | GenBank | WP_012489500 |
| Name | traG_RHEC894_RS25120_pRheCIAT894c |
UniProt ID | _ |
| Length | 639 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 639 a.a. Molecular weight: 70607.76 Da Isoelectric Point: 9.5676
>WP_012489500.1 MULTISPECIES: Ti-type conjugative transfer system protein TraG [Rhizobium]
MGLRGKPHPSLLLVLVPIAVTTITIYIVGWRWPGLAAGMSGKIEHWFLRAAPVPPLLFGPLAGLLTVWAL
PLHRRRPVAMASLLYFLGVAAFYALREFGRLAPAVQAEVITWDRALSYLDMVAVIAAVAGFMAVAMSARI
SVVVPDEIKRARRGIFGDADWLPMTAAGKLFPPEGEIVVGERYRVDKEIVHALPFDANDRSTWGQGGKAP
LLTYRQDFDSTHMLFFAGSGGYKTTSNVVPTALRYSGPLICLDPSTEVAPMVAGHRARALKREVMVLDPT
NPIMGFNVLDGIEASKQKEEDIVGIAHMLLSESLRFESSTGSYFQNQAHNLLTGLLAHVMLSPEYEGRRS
LRSLRQIVSEPEPSVLAMLRDIQEHSGSAFIRETLGVFTNMTEQTFSGVYSTASKDTQWLSLDSYAALVC
GNAFKSSDIVSGKKDVFLNISASILRSYPGIARVIIGSLINAMVQADGAFQRRALFMLDEVDLLGYMRVL
EEARDRGRKYGISMMLMYQSVGQLERHFGKDGATSWIDGCAFASYAAIKALDTARNVSAQCGEMTVEVKG
SSRNIGWDTKNNASRRSENVNFQRRPLIMPHEITQSMRKDEQIIIVQGHSPIRCGRAIYFRRKEMDQAAK
VNRFVKPVL
MGLRGKPHPSLLLVLVPIAVTTITIYIVGWRWPGLAAGMSGKIEHWFLRAAPVPPLLFGPLAGLLTVWAL
PLHRRRPVAMASLLYFLGVAAFYALREFGRLAPAVQAEVITWDRALSYLDMVAVIAAVAGFMAVAMSARI
SVVVPDEIKRARRGIFGDADWLPMTAAGKLFPPEGEIVVGERYRVDKEIVHALPFDANDRSTWGQGGKAP
LLTYRQDFDSTHMLFFAGSGGYKTTSNVVPTALRYSGPLICLDPSTEVAPMVAGHRARALKREVMVLDPT
NPIMGFNVLDGIEASKQKEEDIVGIAHMLLSESLRFESSTGSYFQNQAHNLLTGLLAHVMLSPEYEGRRS
LRSLRQIVSEPEPSVLAMLRDIQEHSGSAFIRETLGVFTNMTEQTFSGVYSTASKDTQWLSLDSYAALVC
GNAFKSSDIVSGKKDVFLNISASILRSYPGIARVIIGSLINAMVQADGAFQRRALFMLDEVDLLGYMRVL
EEARDRGRKYGISMMLMYQSVGQLERHFGKDGATSWIDGCAFASYAAIKALDTARNVSAQCGEMTVEVKG
SSRNIGWDTKNNASRRSENVNFQRRPLIMPHEITQSMRKDEQIIIVQGHSPIRCGRAIYFRRKEMDQAAK
VNRFVKPVL
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4SS
T4SS were predicted by using oriTfinder2.
Region 1: 210091..219678
| Locus tag | Coordinates | Strand | Size (bp) | Protein ID | Product | Description |
|---|---|---|---|---|---|---|
| RHEC894_RS33545 | 206585..206811 | - | 227 | Protein_191 | chaperonin GroEL | - |
| RHEC894_RS24985 (RHEC894_PC00203) | 207106..208026 | + | 921 | WP_029875459 | zincin-like metallopeptidase domain-containing protein | - |
| RHEC894_RS24990 | 208137..208319 | - | 183 | WP_009993909 | hypothetical protein | - |
| RHEC894_RS24995 (RHEC894_PC00206) | 209081..209452 | - | 372 | WP_012489483 | hypothetical protein | - |
| RHEC894_RS25000 (RHEC894_PC00207) | 209551..210087 | + | 537 | WP_012489484 | hypothetical protein | - |
| RHEC894_RS25005 (RHEC894_PC00208) | 210091..210732 | + | 642 | WP_012489485 | transglycosylase SLT domain-containing protein | virB1 |
| RHEC894_RS25010 (RHEC894_PC00209) | 210747..211046 | + | 300 | WP_009991942 | TrbC/VirB2 family protein | virB2 |
| RHEC894_RS25015 (RHEC894_PC00210) | 211052..211390 | + | 339 | WP_010068249 | type IV secretion system protein VirB3 | virB3 |
| RHEC894_RS25020 (RHEC894_PC00211) | 211383..213749 | + | 2367 | WP_029875460 | VirB4 family type IV secretion system protein | virb4 |
| RHEC894_RS25025 (RHEC894_PC00212) | 213746..214447 | + | 702 | WP_012489487 | P-type DNA transfer protein VirB5 | virB5 |
| RHEC894_RS25030 (RHEC894_PC00213) | 214444..214677 | + | 234 | WP_009996882 | EexN family lipoprotein | - |
| RHEC894_RS25035 (RHEC894_PC00214) | 214680..215612 | + | 933 | WP_009996881 | type IV secretion system protein | virB6 |
| RHEC894_RS33550 (RHEC894_PC00215) | 215652..215933 | + | 282 | WP_012489488 | hypothetical protein | - |
| RHEC894_RS25045 (RHEC894_PC00216) | 215935..216606 | + | 672 | WP_029875461 | virB8 family protein | virB8 |
| RHEC894_RS25050 (RHEC894_PC00217) | 216603..217460 | + | 858 | WP_009996879 | P-type conjugative transfer protein VirB9 | virB9 |
| RHEC894_RS25055 (RHEC894_PC00218) | 217469..218641 | + | 1173 | WP_012489490 | type IV secretion system protein VirB10 | virB10 |
| RHEC894_RS25060 (RHEC894_PC00219) | 218650..219678 | + | 1029 | WP_012489491 | P-type DNA transfer ATPase VirB11 | virB11 |
| RHEC894_RS25065 (RHEC894_PC00220) | 219722..220294 | - | 573 | WP_010067915 | PIN domain-containing protein | - |
| RHEC894_RS25070 (RHEC894_PC00221) | 220284..220730 | - | 447 | WP_029875463 | hypothetical protein | - |
| RHEC894_RS25075 (RHEC894_PC00223) | 221243..222433 | - | 1191 | WP_012489493 | DUF1173 domain-containing protein | - |
| RHEC894_RS33555 | 222744..223003 | + | 260 | Protein_211 | toprim domain-containing protein | - |
| RHEC894_RS25080 (RHEC894_PC00225) | 223391..223657 | + | 267 | WP_004676093 | hypothetical protein | - |
| RHEC894_RS25085 (RHEC894_PC00226) | 223654..224052 | + | 399 | WP_008536014 | type II toxin-antitoxin system VapC family toxin | - |
Host bacterium
| ID | 8030 | GenBank | NZ_CP020950 |
| Plasmid name | pRheCIAT894c | Incompatibility group | - |
| Plasmid size | 464024 bp | Coordinate of oriT [Strand] | 229850..229878 [+] |
| Host baterium | Rhizobium sp. CIAT894 |
Cargo genes
| Drug resistance gene | - |
| Virulence gene | hsiC1/vipB |
| Metal resistance gene | - |
| Degradation gene | - |
| Symbiosis gene | fixA, fixB, nifX, nifN, nifE, nifK, nifD, nifH, nifS, nifW, fixC, fixX, nifA, nifB, nifZ, nifT, nodD, nodJ, nodI, nodS, nodC, mLTONO_5203, nodA |
| Anti-CRISPR | - |