Detailed information of oriT
oriT
The information of the oriT region
| oriTDB ID | 104766 |
| Name | oriT_p3020.C01b |
| Organism | Staphylococcus aureus strain 3020.C01 |
| Sequence Completeness | - |
| NCBI accession of oriT (coordinates [strand]) | NZ_CP025497 (10414..10653 [+], 240 nt) |
| oriT length | 240 nt |
| IRs (inverted repeats) | 171..178, 183..190 (TACCCATT..AATGGGTA) 154..160, 164..170 (ATCTGGC..GCCAGAT) 87..93, 98..104 (TGTCACA..TGTGACA) 55..61, 66..72 (TGTCACA..TGTGACA) |
| Location of nic site | _ |
| Conserved sequence flanking the nic site |
_ |
| Note | Predicted by oriTfinder 2.0 |
oriT sequence
Download Length: 240 nt
>oriT_p3020.C01b
GAAATATACACAATAATAGGGGTGGAACACTTTTGTGACAATTTCAATATATTGTGTCACAAAAGTGTGACAATTTCAATATATTGTGTCACAAAAGTGTGACAATTTAATTTTTGTGACCCCCATAAGATAAATGTTTAAAACCCTTGAAATATCTGGCTTCGCCAGATTACCCATTATAAAATGGGTACATATTTCCCTTATGCTCTTACAAATATCTAGCTATATTAGGAGGTAATA
GAAATATACACAATAATAGGGGTGGAACACTTTTGTGACAATTTCAATATATTGTGTCACAAAAGTGTGACAATTTCAATATATTGTGTCACAAAAGTGTGACAATTTAATTTTTGTGACCCCCATAAGATAAATGTTTAAAACCCTTGAAATATCTGGCTTCGCCAGATTACCCATTATAAAATGGGTACATATTTCCCTTATGCTCTTACAAATATCTAGCTATATTAGGAGGTAATA
Visualization of oriT structure
oriT secondary structure
Predicted by RNAfold.
Download structure file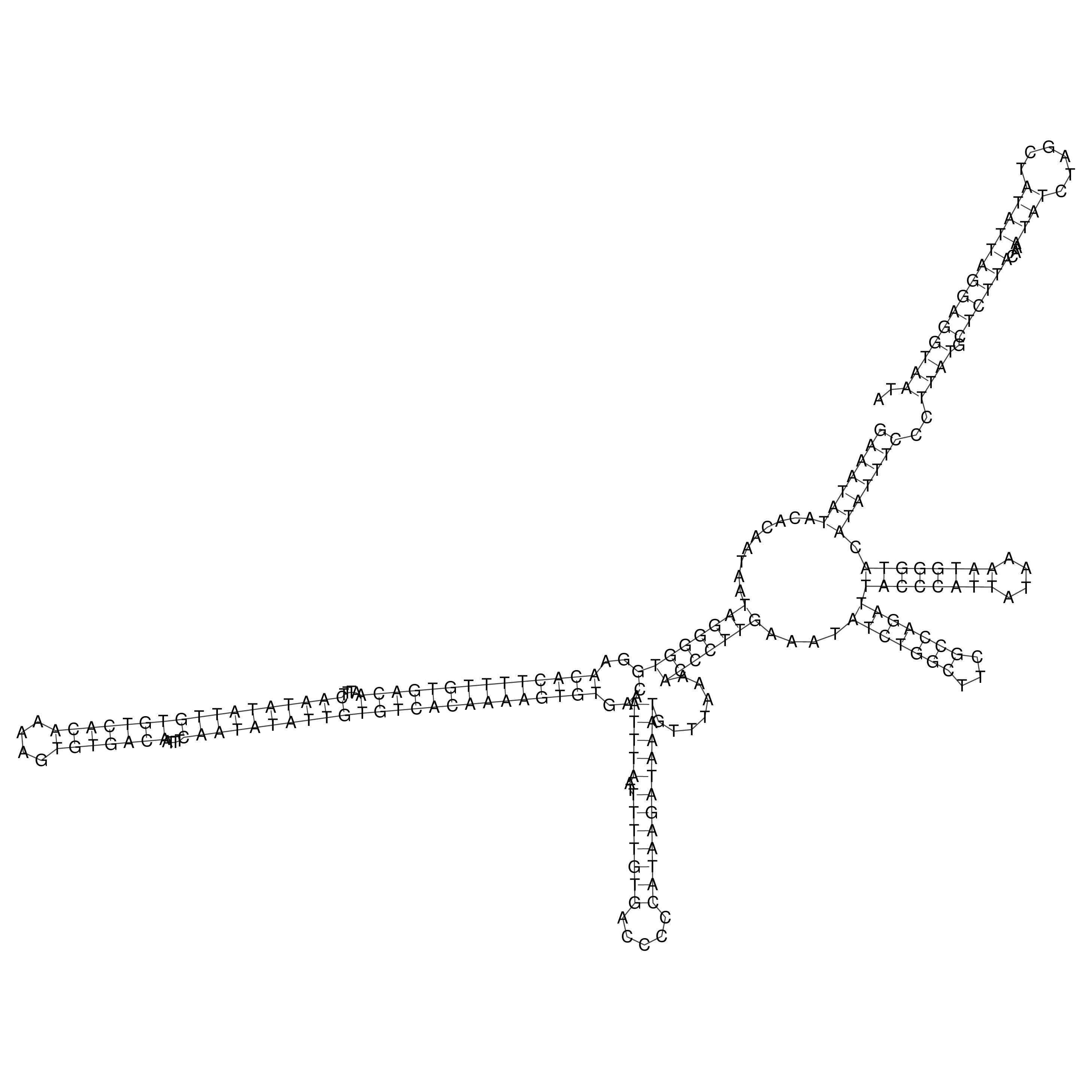
Relaxase
| ID | 3391 | GenBank | WP_031770318 |
| Name | mobP2_A7U46_RS15085_p3020.C01b |
UniProt ID | _ |
| Length | 391 a.a. | PDB ID | |
| Note | Predicted by oriTfinder 2.0 | ||
Relaxase protein sequence
Download Length: 391 a.a. Molecular weight: 47036.61 Da Isoelectric Point: 8.9143
>WP_031770318.1 MULTISPECIES: MobP2 family relaxase [Staphylococcus]
MPKIVTMSEFEQPQNKSNYGNYVNYVDREEAKKNEHEVFQYDVYAHYMFDEQKSNSMFNENSNYMNKNEI
EYTKTKFNEAQKNNGIMWKDVISFDNDSLKEAGIFDPDCKYLDEQKMRQATRKAMQKFEKKEGLENNLVW
SSSIHYNTDNIHVHVAAVEKDVTRERGKRKYSTIKEMKSSFANELFDMSGERTKINNFIRDRIVKGIKEQ
NEPDYNTEMKKQLKKIHEEVKDIPKKEWQYNNNIMKHVRPEIDKFTEMYIKNNHGEEFESFKQDLKKQSK
LYKETYGDKSEYKKYEETKMNDLYSRAGNTILKQLKSFNEEYNGIKYKEPNKLDNKNIPNYNPKATSKMQ
IGYALNNTLYNTQRALRNDFQKERNINQYHYEFDKSYQPEQ
MPKIVTMSEFEQPQNKSNYGNYVNYVDREEAKKNEHEVFQYDVYAHYMFDEQKSNSMFNENSNYMNKNEI
EYTKTKFNEAQKNNGIMWKDVISFDNDSLKEAGIFDPDCKYLDEQKMRQATRKAMQKFEKKEGLENNLVW
SSSIHYNTDNIHVHVAAVEKDVTRERGKRKYSTIKEMKSSFANELFDMSGERTKINNFIRDRIVKGIKEQ
NEPDYNTEMKKQLKKIHEEVKDIPKKEWQYNNNIMKHVRPEIDKFTEMYIKNNHGEEFESFKQDLKKQSK
LYKETYGDKSEYKKYEETKMNDLYSRAGNTILKQLKSFNEEYNGIKYKEPNKLDNKNIPNYNPKATSKMQ
IGYALNNTLYNTQRALRNDFQKERNINQYHYEFDKSYQPEQ
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4CP
| ID | 3330 | GenBank | WP_223289527 |
| Name | t4cp2_A7U46_RS15035_p3020.C01b |
UniProt ID | _ |
| Length | 941 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 941 a.a. Molecular weight: 108591.55 Da Isoelectric Point: 7.4547
>WP_223289527.1 MULTISPECIES: VirD4-like conjugal transfer protein, CD1115 family [Staphylococcus]
MIPFRSKHNHGYHRKKASFSQNKHLLAHPIGLLALLVVGFIFIMLAANFFINMLNNLIFAGGDIFDNMKK
INNEWTNYFFKLRFDLALFYIPFFVLLTVLWGKKVYQIRQKFKSLDNQEKASGRFSTKKEIKQQYKAIAQ
REKQFEGEGGLPVAMFGVYDFATKTKQYLEQRKTAKTEINSMPDLTQDEKYNMKKDKLGQINKEFVSTFF
LKREFTFIDESPTNNIFVGTSRSGKGEVFVLSMIENYSRSSHQPSLVVGDMKGELYSASNETLENRNYHT
EVFNLDQPMESTMSFNLLQLVIEEYQKGDLGEAQEMTKQITHTLTNNEGVEDNEWNLMSAALINAMILAL
CEEALPEHPEKVTLYSVSNMLQTLSVKKFYKQIQIGNQVKVIETSALDEYMERFPSHSPAKTQYATVEAA
PDKMRSSIIGTALKALQPFTTDTIAKLTSHSSLDLNKLGFPSIIDGFSEPDSKFELNVQVKRETNIGTKY
DEVEGINIGVNEYGYWQYPFKTVLNIDDRIEIVETDEFNEEVKYYFYVTSIDKKGQVTFEAKGDIYSSNV
TIRKFNSFAKPIAIFMVVPDYNSANHGIASILVNQIVFELSKNSQLYTEKQSTHRRVIFHLDEAGNMPQI
PNLSQKVNVSLSRGLRFNFFVQAFSQIKDTYGDAYDAIMDACQNKVFIMATQEQTLKDFSDMIGSQQITV
RSRSGETDSLKSSITENQEERPLLRADELAHLQEGETVVVRNLKRQDNKRRKVMSYPIFNSGKYAMKYRY
QYLADLMDTGKSIIHFRPLLKERCEHRHLQLETTLVDWEKIIENMQAGIENDSNNDIDDLTQSLNKSMGE
KANANNPEAYKEENNKKPVTRQKKVLTLKAQLSAEEFDRLTRRFTKTIRMYEEDGNNVDRLTLYKLKQYL
KLRVRNNDITEEQKNKSINYVEQLIEEAKAK
MIPFRSKHNHGYHRKKASFSQNKHLLAHPIGLLALLVVGFIFIMLAANFFINMLNNLIFAGGDIFDNMKK
INNEWTNYFFKLRFDLALFYIPFFVLLTVLWGKKVYQIRQKFKSLDNQEKASGRFSTKKEIKQQYKAIAQ
REKQFEGEGGLPVAMFGVYDFATKTKQYLEQRKTAKTEINSMPDLTQDEKYNMKKDKLGQINKEFVSTFF
LKREFTFIDESPTNNIFVGTSRSGKGEVFVLSMIENYSRSSHQPSLVVGDMKGELYSASNETLENRNYHT
EVFNLDQPMESTMSFNLLQLVIEEYQKGDLGEAQEMTKQITHTLTNNEGVEDNEWNLMSAALINAMILAL
CEEALPEHPEKVTLYSVSNMLQTLSVKKFYKQIQIGNQVKVIETSALDEYMERFPSHSPAKTQYATVEAA
PDKMRSSIIGTALKALQPFTTDTIAKLTSHSSLDLNKLGFPSIIDGFSEPDSKFELNVQVKRETNIGTKY
DEVEGINIGVNEYGYWQYPFKTVLNIDDRIEIVETDEFNEEVKYYFYVTSIDKKGQVTFEAKGDIYSSNV
TIRKFNSFAKPIAIFMVVPDYNSANHGIASILVNQIVFELSKNSQLYTEKQSTHRRVIFHLDEAGNMPQI
PNLSQKVNVSLSRGLRFNFFVQAFSQIKDTYGDAYDAIMDACQNKVFIMATQEQTLKDFSDMIGSQQITV
RSRSGETDSLKSSITENQEERPLLRADELAHLQEGETVVVRNLKRQDNKRRKVMSYPIFNSGKYAMKYRY
QYLADLMDTGKSIIHFRPLLKERCEHRHLQLETTLVDWEKIIENMQAGIENDSNNDIDDLTQSLNKSMGE
KANANNPEAYKEENNKKPVTRQKKVLTLKAQLSAEEFDRLTRRFTKTIRMYEEDGNNVDRLTLYKLKQYL
KLRVRNNDITEEQKNKSINYVEQLIEEAKAK
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
Host bacterium
| ID | 5205 | GenBank | NZ_CP025497 |
| Plasmid name | p3020.C01b | Incompatibility group | - |
| Plasmid size | 61505 bp | Coordinate of oriT [Strand] | 10414..10653 [+] |
| Host baterium | Staphylococcus aureus strain 3020.C01 |
Cargo genes
| Drug resistance gene | msr(A), mph(C), qacA, blaZ |
| Virulence gene | - |
| Metal resistance gene | - |
| Degradation gene | - |
| Symbiosis gene | - |
| Anti-CRISPR | AcrIIA21 |