Detailed information of oriT
oriT
The information of the oriT region
| oriTDB ID | 103854 |
| Name | oriT_Rm41|psymB |
| Organism | Sinorhizobium meliloti strain Rm41 |
| Sequence Completeness | - |
| NCBI accession of oriT (coordinates [strand]) | NZ_CP021810 (116391..116419 [-], 29 nt) |
| oriT length | 29 nt |
| IRs (inverted repeats) | 14..19, 24..29 (CGTCGC..GCGACG) |
| Location of nic site | _ |
| Conserved sequence flanking the nic site |
_ |
| Note | Predicted by oriTfinder 2.0 |
oriT sequence
Download Length: 29 nt
>oriT_Rm41|psymB
AGGGCGCAATATACGTCGCTGGCGCGACG
AGGGCGCAATATACGTCGCTGGCGCGACG
Visualization of oriT structure
oriT secondary structure
Predicted by RNAfold.
Download structure file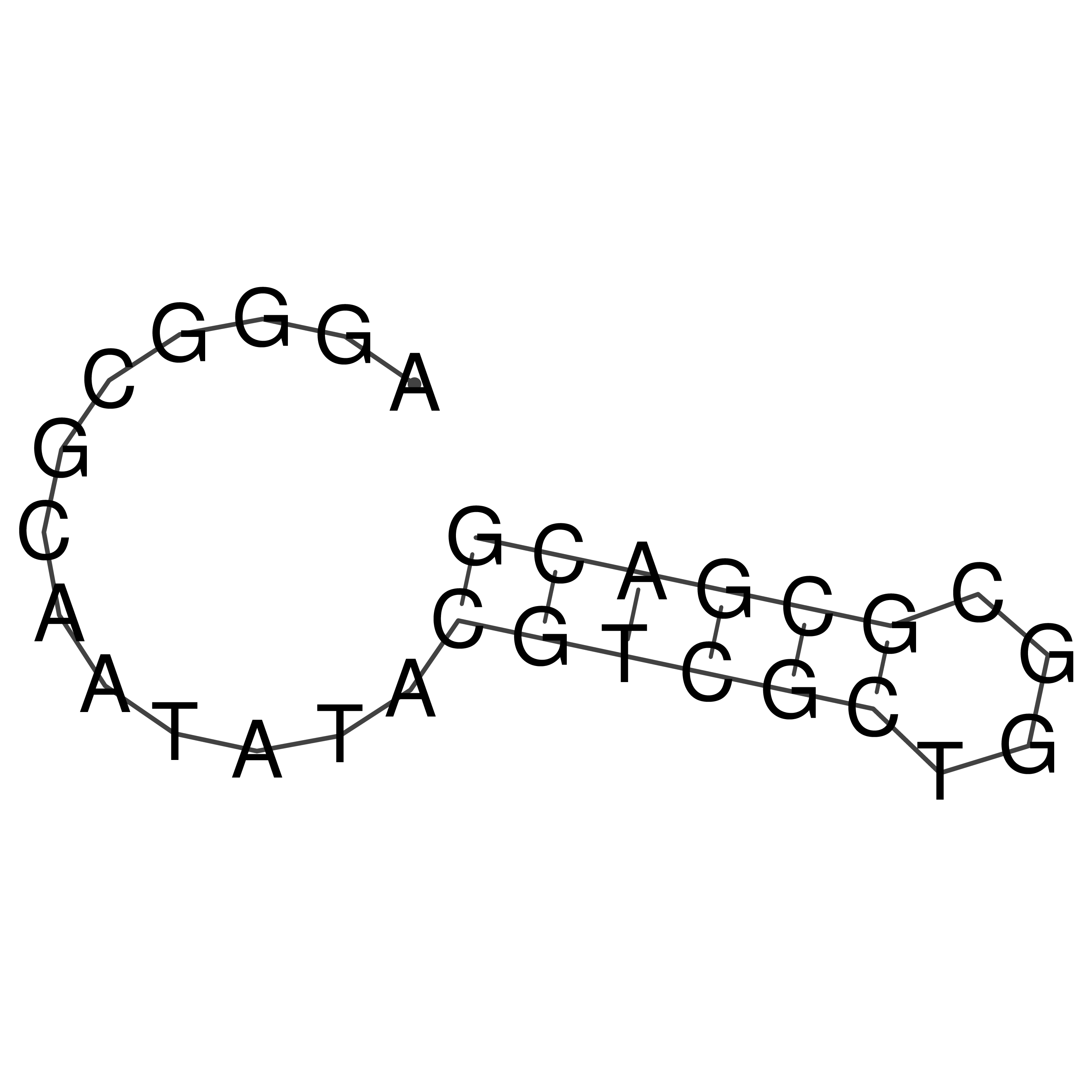
Relaxase
| ID | 2865 | GenBank | WP_088195426 |
| Name | traA_CDO27_RS27045_Rm41|psymB |
UniProt ID | _ |
| Length | 1539 a.a. | PDB ID | |
| Note | Predicted by oriTfinder 2.0 | ||
Relaxase protein sequence
Download Length: 1539 a.a. Molecular weight: 170014.80 Da Isoelectric Point: 9.4868
>WP_088195426.1 Ti-type conjugative transfer relaxase TraA [Sinorhizobium meliloti]
MAIMFVRAQVIGRGAGRSIVSAAAYRHRTRMIDEQAGTSFSYRGGASELVHEELALPDDIPAWLKAAIDG
RSVAKASEALWNAVEAHETRADAQLARELIIALPEELTRAENIALVREFVRDNLTSKGMVADWVYHDKDG
NPHIHLMTALRPLTEEGFGPKKVPVLSEDGEPLRVVTPDRPNGKIVYKLWAGDKETIKAWKIAWAETANR
HLALAGHEIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGIAMYFAPADLARRQEMADRLLAEPELLLKQ
LGNERSTFDERDIARALHRYVDDPVDFANIRARLMASDELVLLKPQQVDAEAGEAKQPAVFTTREMLRLE
YAMARSAEVLSRRKGFGVSNARAAAAVRSIETADTEKPFRLDPEQVDAVRHVTRDNAIAAVVGLAGAGKS
TLLAAARVAWEGEGRRVIGAALAGKAAEGLEDSSGIRSRTLASWELAWESGREQLNRGDVLVIDEAGMVS
SQQMARILKAVEDAGAKAVLVGDAMQLQPIEAGAAFRAITERIGFAELAGVRRQRDAWARDASRLFARGK
VEEGLDAYAQQGRIVETETRAEIVDRIVADWANARRDLLQKSADGEHPGRLRGDELLVLAHTNDDVRKLN
EALRQVMIGEGALAGAREFQTARGLREFAAGDRIIFLENARFVEPRARRLGPQYVKNGMLGTVVSTGDRR
GDTLLSVRLDSGRDVVISQDSYRNVDHGYAATIHKSQGSTVDRTFVLATGMMDQHLTYVAMTRHRDRADL
YAAKEDFEAKPEWGRKPRVDHAAVVTGELVKEGMAKFRPNDEDADESPYADIRTDDGTVNRLWGVSLPKA
LKDAGVAEGDTITLRKDGVERVKVQVPIVDEQTGEKRFEERQVDRNVWSASQLETAAARRERIERESHRP
QLFAALVERLSRSGAKTTTLDFEDEAGYQAQARDFARRRGLYHLSLVAAGMEAEVLRRWAGIAEKREQVA
KLWERASVALGFAIERERRVAYNEERTETLSTGIPSDGKYLVPPTTTFSRSVAEDARLAQLSSQRWKERE
AIVHPVLAKVYRDPDGALSALNALASDAAIEPRKLAEDLGLAPDRLGRLRGSELVVDGRAARDERTAATV
ALSELLPLARAHATEFRRNAERFGIREQQRRAHMALSVPALSKTAMARLVEIEAVRKQGGDDAYRTAFAY
AVEDRLLVQEVKAVNEALTARFGWSAFTAKADVIAERNIAERMPEDLAPERREKLKRLFAVIRRFAEEQH
LAERQDRSKIVAGASVELGKGTFAVLPMLAPVTEFKTTVDEEARERALAAPHYAHHRAALVETATRVWRD
PADAIGKIEDLIVKGFAAERIAAAVTNDPAAYGALRGSDRIMDKLLAVGRERKGALQAVPEAASRIRSLG
ASYASALDAETRSITEERRRMAVAIPGLSPAAEDALKRLAAQIKNKDGKLDVAAGSLDPRIAREFAKVSR
ALDERFGRNAILRGETDVINRVSPAQRRAFEAMRDRLTILQQAVRIQSSQKIVSERRQRAINQSRGIRM
MAIMFVRAQVIGRGAGRSIVSAAAYRHRTRMIDEQAGTSFSYRGGASELVHEELALPDDIPAWLKAAIDG
RSVAKASEALWNAVEAHETRADAQLARELIIALPEELTRAENIALVREFVRDNLTSKGMVADWVYHDKDG
NPHIHLMTALRPLTEEGFGPKKVPVLSEDGEPLRVVTPDRPNGKIVYKLWAGDKETIKAWKIAWAETANR
HLALAGHEIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGIAMYFAPADLARRQEMADRLLAEPELLLKQ
LGNERSTFDERDIARALHRYVDDPVDFANIRARLMASDELVLLKPQQVDAEAGEAKQPAVFTTREMLRLE
YAMARSAEVLSRRKGFGVSNARAAAAVRSIETADTEKPFRLDPEQVDAVRHVTRDNAIAAVVGLAGAGKS
TLLAAARVAWEGEGRRVIGAALAGKAAEGLEDSSGIRSRTLASWELAWESGREQLNRGDVLVIDEAGMVS
SQQMARILKAVEDAGAKAVLVGDAMQLQPIEAGAAFRAITERIGFAELAGVRRQRDAWARDASRLFARGK
VEEGLDAYAQQGRIVETETRAEIVDRIVADWANARRDLLQKSADGEHPGRLRGDELLVLAHTNDDVRKLN
EALRQVMIGEGALAGAREFQTARGLREFAAGDRIIFLENARFVEPRARRLGPQYVKNGMLGTVVSTGDRR
GDTLLSVRLDSGRDVVISQDSYRNVDHGYAATIHKSQGSTVDRTFVLATGMMDQHLTYVAMTRHRDRADL
YAAKEDFEAKPEWGRKPRVDHAAVVTGELVKEGMAKFRPNDEDADESPYADIRTDDGTVNRLWGVSLPKA
LKDAGVAEGDTITLRKDGVERVKVQVPIVDEQTGEKRFEERQVDRNVWSASQLETAAARRERIERESHRP
QLFAALVERLSRSGAKTTTLDFEDEAGYQAQARDFARRRGLYHLSLVAAGMEAEVLRRWAGIAEKREQVA
KLWERASVALGFAIERERRVAYNEERTETLSTGIPSDGKYLVPPTTTFSRSVAEDARLAQLSSQRWKERE
AIVHPVLAKVYRDPDGALSALNALASDAAIEPRKLAEDLGLAPDRLGRLRGSELVVDGRAARDERTAATV
ALSELLPLARAHATEFRRNAERFGIREQQRRAHMALSVPALSKTAMARLVEIEAVRKQGGDDAYRTAFAY
AVEDRLLVQEVKAVNEALTARFGWSAFTAKADVIAERNIAERMPEDLAPERREKLKRLFAVIRRFAEEQH
LAERQDRSKIVAGASVELGKGTFAVLPMLAPVTEFKTTVDEEARERALAAPHYAHHRAALVETATRVWRD
PADAIGKIEDLIVKGFAAERIAAAVTNDPAAYGALRGSDRIMDKLLAVGRERKGALQAVPEAASRIRSLG
ASYASALDAETRSITEERRRMAVAIPGLSPAAEDALKRLAAQIKNKDGKLDVAAGSLDPRIAREFAKVSR
ALDERFGRNAILRGETDVINRVSPAQRRAFEAMRDRLTILQQAVRIQSSQKIVSERRQRAINQSRGIRM
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4CP
| ID | 2701 | GenBank | WP_013850291 |
| Name | tcpA_CDO27_RS35980_Rm41|psymB |
UniProt ID | _ |
| Length | 946 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 946 a.a. Molecular weight: 101616.47 Da Isoelectric Point: 4.6107
>WP_013850291.1 FtsK/SpoIIIE domain-containing protein [Sinorhizobium meliloti]
MRIPRTNFSPAALYDANHADDYEDPHPAAQGAAHVPAAPEAAAHDHLFEAPEAPRRAPGHRDEETGYAGR
AARLYGHGSAYAPAEVTVSTRDPLPTLAEITGLSGEPGWESHFFLSPNVRFTRTPERELMKRHPPAPEES
RIEADEAAAEASDAETVMDVVPAEPAPSVVETELPSYSPSELLRVLTQQLPSWSAARSQAPEASVTKPAI
TESVAVAEEKPATSETTALPVTDEVPVVPHALPVANLAPESAAVEEDVPHQADARLAYLSDFAFFEFMPL
EVAAVPPTVTEPVKEAARIPAPIAAAPKVSPPKIVAAMPVEIRPQPPTAISSLFRVVECRRPEPATAEPV
TAAPQDIAAEPAAAEAAALPAPRVVETPAPALAEPAIVPASEPAPEAPVTRAAITMPAVIQRSSPSLPPI
GAIEPLQGGDAYEFPSKELLQEPPQGQGFFMTQEQLEQNAGLLESVLEDFGVKGEIIHVRPGPVVTLYEF
EPAPGVKSSRVIGLADDIARSMSALSARVAVVPGRNVIGIELPNATRETVYFRELIESGDFQKTGCKLAL
CLGKTIGGEPVIAELAKMPHLLVAGTTGSGKSVAINTMILSLLYRLKPEECRLIMVDPKMLELSVYDGIP
HLLTPVVTDPKKAVMALKWAVREMEDRYRKMSRLGVRNIDGYNQRAAAAREKGAPILATVQTGFEKGTGE
PLFEQQEMDLSPMPYIVVIVDEMADLMMVAGKEIEGAIQRLAQMARAAGIHLIMATQRPSVDVITGTIKA
NFPTRISFQVTSKIDSRTILGEQGAEQLLGQGDMLHMAGGGRIARVHGPFVSDQEVEHVVAHLKTQGRPE
YLETVTADEEEEEVEEDQGAVFDKSAIAAEDGNELYDQAVKVVLRDKKCSTSYIQRRLGIGYNRAASLVE
RMEKDGLVGPANHVGKREIIYGNRDNAPKPESDDLD
MRIPRTNFSPAALYDANHADDYEDPHPAAQGAAHVPAAPEAAAHDHLFEAPEAPRRAPGHRDEETGYAGR
AARLYGHGSAYAPAEVTVSTRDPLPTLAEITGLSGEPGWESHFFLSPNVRFTRTPERELMKRHPPAPEES
RIEADEAAAEASDAETVMDVVPAEPAPSVVETELPSYSPSELLRVLTQQLPSWSAARSQAPEASVTKPAI
TESVAVAEEKPATSETTALPVTDEVPVVPHALPVANLAPESAAVEEDVPHQADARLAYLSDFAFFEFMPL
EVAAVPPTVTEPVKEAARIPAPIAAAPKVSPPKIVAAMPVEIRPQPPTAISSLFRVVECRRPEPATAEPV
TAAPQDIAAEPAAAEAAALPAPRVVETPAPALAEPAIVPASEPAPEAPVTRAAITMPAVIQRSSPSLPPI
GAIEPLQGGDAYEFPSKELLQEPPQGQGFFMTQEQLEQNAGLLESVLEDFGVKGEIIHVRPGPVVTLYEF
EPAPGVKSSRVIGLADDIARSMSALSARVAVVPGRNVIGIELPNATRETVYFRELIESGDFQKTGCKLAL
CLGKTIGGEPVIAELAKMPHLLVAGTTGSGKSVAINTMILSLLYRLKPEECRLIMVDPKMLELSVYDGIP
HLLTPVVTDPKKAVMALKWAVREMEDRYRKMSRLGVRNIDGYNQRAAAAREKGAPILATVQTGFEKGTGE
PLFEQQEMDLSPMPYIVVIVDEMADLMMVAGKEIEGAIQRLAQMARAAGIHLIMATQRPSVDVITGTIKA
NFPTRISFQVTSKIDSRTILGEQGAEQLLGQGDMLHMAGGGRIARVHGPFVSDQEVEHVVAHLKTQGRPE
YLETVTADEEEEEVEEDQGAVFDKSAIAAEDGNELYDQAVKVVLRDKKCSTSYIQRRLGIGYNRAASLVE
RMEKDGLVGPANHVGKREIIYGNRDNAPKPESDDLD
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
Host bacterium
| ID | 4294 | GenBank | NZ_CP021810 |
| Plasmid name | Rm41|psymB | Incompatibility group | - |
| Plasmid size | 1665079 bp | Coordinate of oriT [Strand] | 116391..116419 [-] |
| Host baterium | Sinorhizobium meliloti strain Rm41 |
Cargo genes
| Drug resistance gene | - |
| Virulence gene | htpB |
| Metal resistance gene | actP |
| Degradation gene | - |
| Symbiosis gene | - |
| Anti-CRISPR | AcrIIA7 |