Detailed information of oriT
oriT
The information of the oriT region
| oriTDB ID | 103839 |
| Name | oriT_USDA1106|psymA |
| Organism | Sinorhizobium meliloti strain USDA1106 |
| Sequence Completeness | - |
| NCBI accession of oriT (coordinates [strand]) | NZ_CP021798 (201611..201639 [-], 29 nt) |
| oriT length | 29 nt |
| IRs (inverted repeats) | 14..19, 24..29 (CGTCGC..GCGACG) |
| Location of nic site | _ |
| Conserved sequence flanking the nic site |
_ |
| Note | Predicted by oriTfinder 2.0 |
oriT sequence
Download Length: 29 nt
>oriT_USDA1106|psymA
AGGGCGCAATATACGTCGCTGGCGCGACG
AGGGCGCAATATACGTCGCTGGCGCGACG
Visualization of oriT structure
oriT secondary structure
Predicted by RNAfold.
Download structure file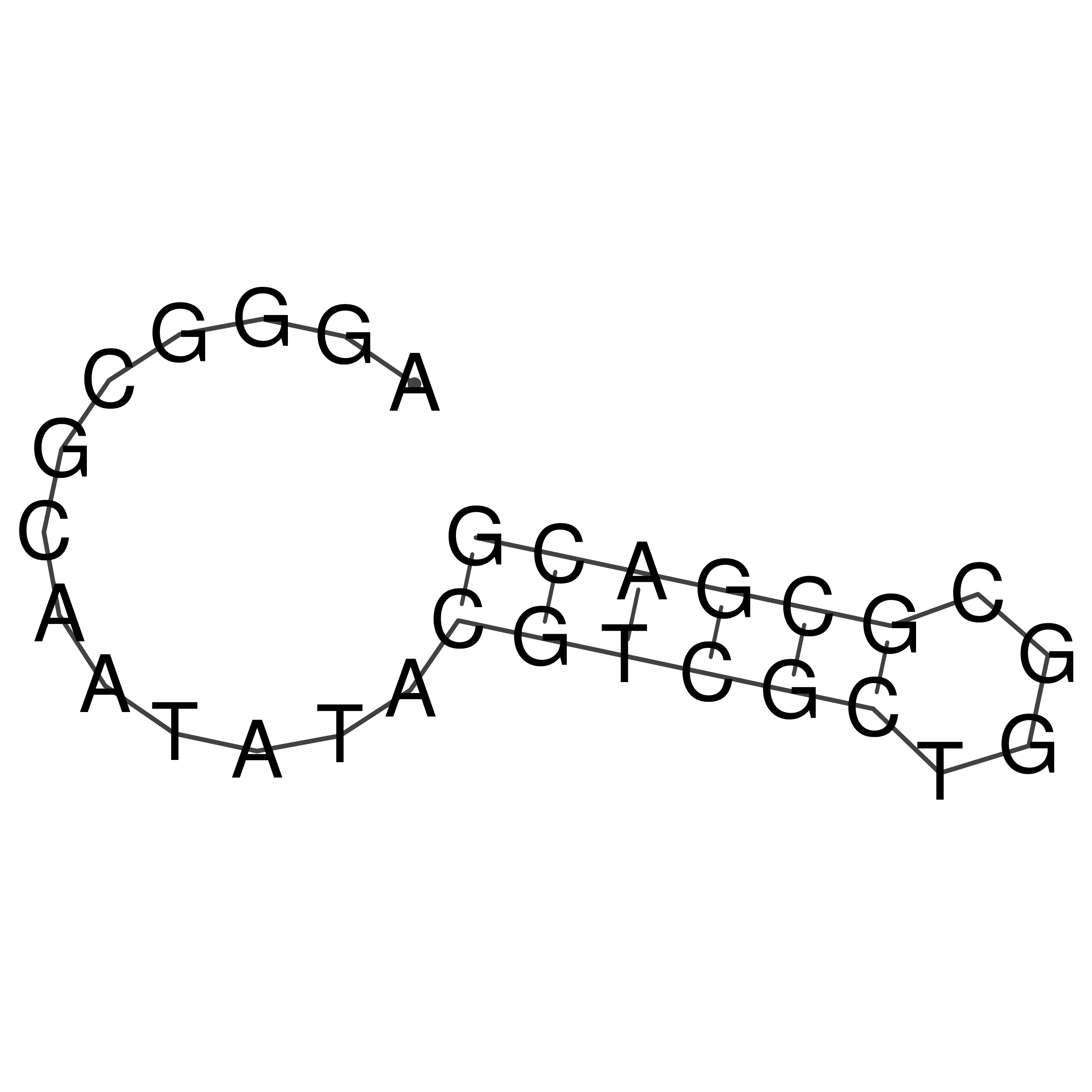
Relaxase
| ID | 2849 | GenBank | WP_010967486 |
| Name | traA_CDO30_RS18965_USDA1106|psymA |
UniProt ID | Q92ZI0 |
| Length | 1539 a.a. | PDB ID | |
| Note | Predicted by oriTfinder 2.0 | ||
Relaxase protein sequence
Download Length: 1539 a.a. Molecular weight: 169953.57 Da Isoelectric Point: 9.4213
>WP_010967486.1 Ti-type conjugative transfer relaxase TraA [Sinorhizobium meliloti]
MAIMFVRAQVISRGAGRSIVSAAAYRHRARMIDEQAGTSFSYRGGASELVHEELALPDDIPAWLRAAIDG
RSVAKASEALWNAVEAHETRADAQLARELIIALPEELTRAENIALVREFVRDNLTSKGMVADWVYHDKDG
NPHIHLMTALRPLTEQGFGPKKVPVLGEDGEPLRVITPDRPNGKIVYKLWAGDKETIKAWKIAWAETANR
HLALAGHEIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGIAMYFAPADLARRQEMADRLLAEPGLLLKQ
LGNERSTFDERDIAKALHRYVDDPVDFANIRARLMASDELVLLKPQQIDAETGKAKQPAVFTTREMLRLE
YAMARSAEVLSRRKGFGVSNARAAAAVRSIETADTEKPFRLDPEQVDAVRHVTRDNAIAAVVGLAGAGKS
TLLAAARAAWEGEGRRVIGAALAGKAAEGLEDSSGIRSRTLASWELAWENGREQLNRGDVLVIDEAGMVS
SQQMARVLKAVEDAGAKAVLVGDAMQLQPIEAGAAFRAISERIGFAELAGVRRQRDAWARDASRLFARGK
VEEGLDAYAQQGRIVETETRAEIVDRIVADWADARRDLLQKSADGEHPGRLRGDELLVLAHTNDDVRKLN
EALRNVMIGEGALAGAREFQTARGLREFAAGDRIIFLENARFVEPRARRLGPQYVKNGMLGTIVSTGDRR
GDTLLSVRLDSGRDVVISQDSYRNVDHGYAATIHKSQGSTVDRTFVLATGMMDQHLTYVAMTRHRDRADL
YAAKEDFEAKPEWGRKPRVDHAAGVTGELVKEGMAKFRPNDEDADESPYADIRTDDGTVQRLWGVSLPKA
LKDAGVAEGDTITLRKDGVERVKVQVPIVDAQTGEKRFEERQVDRNVWSASQLETAAARQERIERESHRP
QLFKQLVERLSRSGAKTTTLDFEDEAGYQAQARDFARRRGLYHLSLVAAGMEAEVLRRWAGIAEKREQVA
KLWERASVALGFAIERERRVAYNEERTETLSTGIPSDGKYLVPPTTTFSRSVAEDARLAQLSSQRWKERE
AIVHPVLAKIYRDPDGALAALNALASDAAIEPRKLAEDLGKAPDRLGRLRGSELVVDGRAARDERTAATV
ALSELLPLARAHATEFRRNAERFGIREQQRRAHMALSVPALSKTAMARLVEIEAVREQGGDDAYRTAFTY
AVEDRLLVQEVKAVNEALTARFGWSAFTAKADVIAERNIAERMPEDLAPERREKLTRLFAVIRRFAEEQH
LAERQDRSKIVAGASVELGKETFAVLPMLAAVTEFKTTVDEEARERALAAPHYAHHRAALVETATRVWRD
PADAIGKIEDLIVKGFAGERIAAAVSNDPAAYGALRGSDRIMDKLLAVGRERKGALQAVPEAASRIRSLG
ASYASALDAETRGITEERRRMAVAIPGLSPAAEDALKRLAAQIKNKDGKLDVAAGSLDPHIAREFAKVSR
ALDQRFGRNAILRGETDVINRVSPAQRRAFEAMRDRLTILQQAVRVQSSQEIISERQRRVIDRARSVTR
MAIMFVRAQVISRGAGRSIVSAAAYRHRARMIDEQAGTSFSYRGGASELVHEELALPDDIPAWLRAAIDG
RSVAKASEALWNAVEAHETRADAQLARELIIALPEELTRAENIALVREFVRDNLTSKGMVADWVYHDKDG
NPHIHLMTALRPLTEQGFGPKKVPVLGEDGEPLRVITPDRPNGKIVYKLWAGDKETIKAWKIAWAETANR
HLALAGHEIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGIAMYFAPADLARRQEMADRLLAEPGLLLKQ
LGNERSTFDERDIAKALHRYVDDPVDFANIRARLMASDELVLLKPQQIDAETGKAKQPAVFTTREMLRLE
YAMARSAEVLSRRKGFGVSNARAAAAVRSIETADTEKPFRLDPEQVDAVRHVTRDNAIAAVVGLAGAGKS
TLLAAARAAWEGEGRRVIGAALAGKAAEGLEDSSGIRSRTLASWELAWENGREQLNRGDVLVIDEAGMVS
SQQMARVLKAVEDAGAKAVLVGDAMQLQPIEAGAAFRAISERIGFAELAGVRRQRDAWARDASRLFARGK
VEEGLDAYAQQGRIVETETRAEIVDRIVADWADARRDLLQKSADGEHPGRLRGDELLVLAHTNDDVRKLN
EALRNVMIGEGALAGAREFQTARGLREFAAGDRIIFLENARFVEPRARRLGPQYVKNGMLGTIVSTGDRR
GDTLLSVRLDSGRDVVISQDSYRNVDHGYAATIHKSQGSTVDRTFVLATGMMDQHLTYVAMTRHRDRADL
YAAKEDFEAKPEWGRKPRVDHAAGVTGELVKEGMAKFRPNDEDADESPYADIRTDDGTVQRLWGVSLPKA
LKDAGVAEGDTITLRKDGVERVKVQVPIVDAQTGEKRFEERQVDRNVWSASQLETAAARQERIERESHRP
QLFKQLVERLSRSGAKTTTLDFEDEAGYQAQARDFARRRGLYHLSLVAAGMEAEVLRRWAGIAEKREQVA
KLWERASVALGFAIERERRVAYNEERTETLSTGIPSDGKYLVPPTTTFSRSVAEDARLAQLSSQRWKERE
AIVHPVLAKIYRDPDGALAALNALASDAAIEPRKLAEDLGKAPDRLGRLRGSELVVDGRAARDERTAATV
ALSELLPLARAHATEFRRNAERFGIREQQRRAHMALSVPALSKTAMARLVEIEAVREQGGDDAYRTAFTY
AVEDRLLVQEVKAVNEALTARFGWSAFTAKADVIAERNIAERMPEDLAPERREKLTRLFAVIRRFAEEQH
LAERQDRSKIVAGASVELGKETFAVLPMLAAVTEFKTTVDEEARERALAAPHYAHHRAALVETATRVWRD
PADAIGKIEDLIVKGFAGERIAAAVSNDPAAYGALRGSDRIMDKLLAVGRERKGALQAVPEAASRIRSLG
ASYASALDAETRGITEERRRMAVAIPGLSPAAEDALKRLAAQIKNKDGKLDVAAGSLDPHIAREFAKVSR
ALDQRFGRNAILRGETDVINRVSPAQRRAFEAMRDRLTILQQAVRVQSSQEIISERQRRVIDRARSVTR
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4CP
| ID | 2680 | GenBank | WP_010967483 |
| Name | traG_CDO30_RS18980_USDA1106|psymA |
UniProt ID | _ |
| Length | 639 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 639 a.a. Molecular weight: 70304.29 Da Isoelectric Point: 9.5501
>WP_010967483.1 Ti-type conjugative transfer system protein TraG [Sinorhizobium meliloti]
MALKAKPHPSLLVILFPVAVTAAAVYVVGWRWPGLAAGMSGKTAYWFLRAAPVPALLFGPLAGLLAVWAL
PLHRRRPVAMASLACFLTVAGFYALREFGRLSPSVESGALSWDRALSYLDMVAVVGAVVGFMAVAVSARI
STVVPEPVKRAKRGTFGDADWLPMAAAGKLFPPDGEIVIGERYRVDKDIVHELPFEPNDPATWGQGGKAP
LLTYRQDFDSTHMLFFAGSGGYKTTSNVVPTALRYTGPLICLDPSTEVAPMVVEHRTRVLGREVMVLDPT
NPIMGFNVLDGIEHSRQKEEDIVGIAHMLLSESVRFESSTGSYFQNQAHNLLTGLLAHVMLSPEYAGRRT
LRSLRQIVSEPEPSVLAMLRDIQERSASTFIRETLGVFTNMTEQTFSGVYSTASKDTQWLSLDSYAALVC
GNAFKSSDIVSGKKDVFLNIPASILRSYPGIGRVIIGSLINAMIQADGSFKRRALFMLDEVDLLGYMRLL
EEARDRGRKYGISMMLLYQSLGQLERHFGRDGAVSWIDGCAFASYAAVKALDTARNISAQCGEMTVEVKG
SSRNIGWDTKNSASRKSENVNYQRRPLIMPHEITQSMRKDEQIIIVQGHSPIRCGRAIYFRRKDMNEAAK
ANRFVKAIP
MALKAKPHPSLLVILFPVAVTAAAVYVVGWRWPGLAAGMSGKTAYWFLRAAPVPALLFGPLAGLLAVWAL
PLHRRRPVAMASLACFLTVAGFYALREFGRLSPSVESGALSWDRALSYLDMVAVVGAVVGFMAVAVSARI
STVVPEPVKRAKRGTFGDADWLPMAAAGKLFPPDGEIVIGERYRVDKDIVHELPFEPNDPATWGQGGKAP
LLTYRQDFDSTHMLFFAGSGGYKTTSNVVPTALRYTGPLICLDPSTEVAPMVVEHRTRVLGREVMVLDPT
NPIMGFNVLDGIEHSRQKEEDIVGIAHMLLSESVRFESSTGSYFQNQAHNLLTGLLAHVMLSPEYAGRRT
LRSLRQIVSEPEPSVLAMLRDIQERSASTFIRETLGVFTNMTEQTFSGVYSTASKDTQWLSLDSYAALVC
GNAFKSSDIVSGKKDVFLNIPASILRSYPGIGRVIIGSLINAMIQADGSFKRRALFMLDEVDLLGYMRLL
EEARDRGRKYGISMMLLYQSLGQLERHFGRDGAVSWIDGCAFASYAAVKALDTARNISAQCGEMTVEVKG
SSRNIGWDTKNSASRKSENVNYQRRPLIMPHEITQSMRKDEQIIIVQGHSPIRCGRAIYFRRKDMNEAAK
ANRFVKAIP
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
Host bacterium
| ID | 4279 | GenBank | NZ_CP021798 |
| Plasmid name | USDA1106|psymA | Incompatibility group | - |
| Plasmid size | 1363628 bp | Coordinate of oriT [Strand] | 201611..201639 [-] |
| Host baterium | Sinorhizobium meliloti strain USDA1106 |
Cargo genes
| Drug resistance gene | - |
| Virulence gene | htpB |
| Metal resistance gene | nia, actP, ncrA |
| Degradation gene | - |
| Symbiosis gene | fixN, fixO, fixG, fixS, nodM, nifN, nodD, nodA, nodB, nodC, nodI, nodJ, nodE, nodF, nodH, nifX, nifE, nifK, nifD, nifH, fixA, fixB, fixC, fixX, nifB, fixU |
| Anti-CRISPR | AcrIIA9 |