Detailed information of oriT
oriT
The information of the oriT region
| oriTDB ID | 102918 |
| Name | oriT_pSymB |
| Organism | Sinorhizobium meliloti strain CCMM B554 (FSM-MA) |
| Sequence Completeness | - |
| NCBI accession of oriT (coordinates [strand]) | NZ_CP019586 (695803..695831 [+], 29 nt) |
| oriT length | 29 nt |
| IRs (inverted repeats) | 14..19, 24..29 (CGTCGC..GCGACG) |
| Location of nic site | _ |
| Conserved sequence flanking the nic site |
_ |
| Note | Predicted by oriTfinder 2.0 |
oriT sequence
Download Length: 29 nt
>oriT_pSymB
AGGGCGCAATATACGTCGCTGGCGCGACG
AGGGCGCAATATACGTCGCTGGCGCGACG
Visualization of oriT structure
oriT secondary structure
Predicted by RNAfold.
Download structure file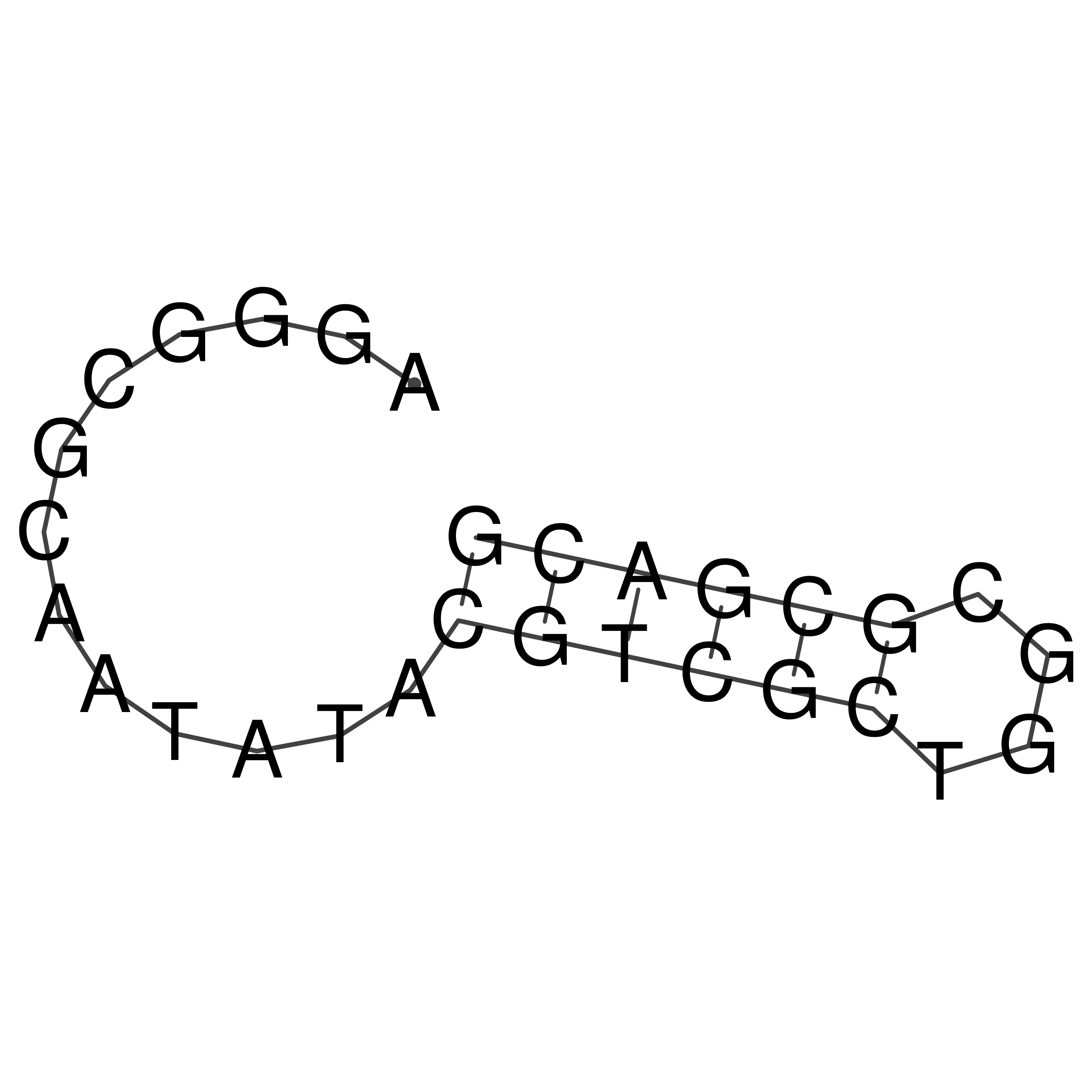
Relaxase
| ID | 2190 | GenBank | WP_088896481 |
| Name | traA_SMB554_RS28980_pSymB |
UniProt ID | _ |
| Length | 1539 a.a. | PDB ID | |
| Note | Predicted by oriTfinder 2.0 | ||
Relaxase protein sequence
Download Length: 1539 a.a. Molecular weight: 169654.39 Da Isoelectric Point: 9.6129
>WP_088896481.1 Ti-type conjugative transfer relaxase TraA [Sinorhizobium meliloti]
MAIMFVRAQVIGRGAGRSIVSAAAYRHRTRMIDEQAGTSFSYRGGASELVHEELALPDDIPAWLKAAIDG
RSVAKASEALWNAVEAHETRADAQLARELIIALPEELTRAENIALVREFVRDNLTSKGMVADWVYHDKDG
NPHIHLMTALRPLTEQGFGPKKVPVLGEDGEPLRVVTPDRPNGKIVYKLWAGDKETIKAWKIAWAETANR
HLALAGHEIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGVAMYFAPADLARRQEMADRLLAEPELLLKQ
LGNERSTFDERDIARALHRYVDDPVDFANIRARLMASDDLVLLKPQQIDAETGKAKQPAVFTTREMLRLE
YAMAQSAEVLSRRKGFGVSNARAAAAARSIETADTEKPFRLDPEQVDAVRHVTRDNAIAAVVGLAGAGKS
TLLAAARVAWEGEGRRVIGAALAGKAAEGLEDSSGIRSRTLASWELAWESGREQLQRGDVLVIDEAGMVS
SQQMARVLKAVEDAGAKAVLVGDAMQLQPIEAGAAFRAITERIGFAELAGVRRQRDAWARDASRLFARGK
VEEGLDAYAQQGRIVETETRAEIVDRIVSDWANARRDLLQKSADGEHPGRLRGDELLVLAHTNDDVRKLN
TSLRNVMIGEGALAGAREFQTARGLREFAAGDRIIFLENARFVEPRARRLGPQYVKNGMLGTVVSTGDRR
GDTLLSVRLDSGRDVVISEDSYRNVDHGYAATIHKSQGSTVDRTFVLATGMMDQHLTYVAMTRHRDRADL
YAAKEDFEAKPEWGRKPRVDHAAGVTGELVKEGMAKFRPNDEDADESPYADIRTDDGTVQRLWGVSLPKA
LKDAGAAEGDTITLRKDGVERVKVQVPIVDAQTGEKRFEERQVDRNVWSASQLETAAARRERIERESHRP
QLFAVLVERLSRSGAKTTTLDFEGEAGYQAQARDFARRRGLYHLSLVAAGMEAEVLRRWAGIAEKREQVA
KLWERASVALGFAIERERRVSYNEERTETLSTGIPSDGKYLVPPTTTFSRSVAEDARLAQLSSQRWKERE
AIVHPVLAKIYRDPDGALSALNALASDAAIEPRKLAEDLGLAPDRLGRLRGSELVVDGRAARDERTAATV
ALSELLPLARAHATEFRRNAERFGIREQQRRAHMALSVPALAKTAMARLVEIEAVRKAGGEDAYRAALTF
AVEDRLLVQEVKAVNEALTARFGWSAFTAKADVIAERNIAERMPEDLAPERREKLTRLFAVIRRFAEEQH
LAERQDRSKIVAGASVELGKGTFAVLPMLAAVTEFKTTVDEEARERALAAPHYAHHRAALVETATRVWRD
PADAIGKIEDLIVKGFAAERIAAAVTNDPAAYGALRGSDRIMDKLLAVGRERKGALQAVPEAASRVRSLG
ASYASALDAETRSITEERRRMAVTIPGLSPAAEDALKRLAAQIKNKDGKLDVAAGSLDPHIAREFAKVSR
ALDERFGRNAILRGETDVINRVSPAQRRAFEAMRDRLTILQQAVRIQSSQKIVSERRQRAINQSRGIRM
MAIMFVRAQVIGRGAGRSIVSAAAYRHRTRMIDEQAGTSFSYRGGASELVHEELALPDDIPAWLKAAIDG
RSVAKASEALWNAVEAHETRADAQLARELIIALPEELTRAENIALVREFVRDNLTSKGMVADWVYHDKDG
NPHIHLMTALRPLTEQGFGPKKVPVLGEDGEPLRVVTPDRPNGKIVYKLWAGDKETIKAWKIAWAETANR
HLALAGHEIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGVAMYFAPADLARRQEMADRLLAEPELLLKQ
LGNERSTFDERDIARALHRYVDDPVDFANIRARLMASDDLVLLKPQQIDAETGKAKQPAVFTTREMLRLE
YAMAQSAEVLSRRKGFGVSNARAAAAARSIETADTEKPFRLDPEQVDAVRHVTRDNAIAAVVGLAGAGKS
TLLAAARVAWEGEGRRVIGAALAGKAAEGLEDSSGIRSRTLASWELAWESGREQLQRGDVLVIDEAGMVS
SQQMARVLKAVEDAGAKAVLVGDAMQLQPIEAGAAFRAITERIGFAELAGVRRQRDAWARDASRLFARGK
VEEGLDAYAQQGRIVETETRAEIVDRIVSDWANARRDLLQKSADGEHPGRLRGDELLVLAHTNDDVRKLN
TSLRNVMIGEGALAGAREFQTARGLREFAAGDRIIFLENARFVEPRARRLGPQYVKNGMLGTVVSTGDRR
GDTLLSVRLDSGRDVVISEDSYRNVDHGYAATIHKSQGSTVDRTFVLATGMMDQHLTYVAMTRHRDRADL
YAAKEDFEAKPEWGRKPRVDHAAGVTGELVKEGMAKFRPNDEDADESPYADIRTDDGTVQRLWGVSLPKA
LKDAGAAEGDTITLRKDGVERVKVQVPIVDAQTGEKRFEERQVDRNVWSASQLETAAARRERIERESHRP
QLFAVLVERLSRSGAKTTTLDFEGEAGYQAQARDFARRRGLYHLSLVAAGMEAEVLRRWAGIAEKREQVA
KLWERASVALGFAIERERRVSYNEERTETLSTGIPSDGKYLVPPTTTFSRSVAEDARLAQLSSQRWKERE
AIVHPVLAKIYRDPDGALSALNALASDAAIEPRKLAEDLGLAPDRLGRLRGSELVVDGRAARDERTAATV
ALSELLPLARAHATEFRRNAERFGIREQQRRAHMALSVPALAKTAMARLVEIEAVRKAGGEDAYRAALTF
AVEDRLLVQEVKAVNEALTARFGWSAFTAKADVIAERNIAERMPEDLAPERREKLTRLFAVIRRFAEEQH
LAERQDRSKIVAGASVELGKGTFAVLPMLAAVTEFKTTVDEEARERALAAPHYAHHRAALVETATRVWRD
PADAIGKIEDLIVKGFAAERIAAAVTNDPAAYGALRGSDRIMDKLLAVGRERKGALQAVPEAASRVRSLG
ASYASALDAETRSITEERRRMAVTIPGLSPAAEDALKRLAAQIKNKDGKLDVAAGSLDPHIAREFAKVSR
ALDERFGRNAILRGETDVINRVSPAQRRAFEAMRDRLTILQQAVRIQSSQKIVSERRQRAINQSRGIRM
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4CP
| ID | 1863 | GenBank | WP_089413699 |
| Name | tcpA_SMB554_RS33505_pSymB |
UniProt ID | _ |
| Length | 946 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 946 a.a. Molecular weight: 101690.47 Da Isoelectric Point: 4.6104
>WP_089413699.1 FtsK/SpoIIIE domain-containing protein [Sinorhizobium meliloti]
MRIPRTNFSPAALYDANHADDYEDPHPAAQGAAHVPAAPEAAAHDHLFEAPEAPRRAPGHRDEETGYAGR
AARLYGHGSAYAPAEVTVSTRDPLPTLAEITGLSGEPGWESHFFLSPNVRFTRTPERELMKRHPPAPEES
RIEADEAAAEASDAETVMDVVPAEPAPSVVETELPSYSPSELLRVLTQQLPSWSAARSQAPEASVTKPAI
TESVAVAEEGPATSETTALPVTDEVPVVPHALPVANLAPESAAVEEDVPHQADARLAYLSDFAFFEFMPL
EVAAVPPTVTEPVKEAARIPAPIAAAPKVSPRKIVAAMPVEIRPQPPTAISSLFRVVECRRPEPATAEPV
TAAPQDIAAEPAAAEAAALPAHQFVETPAPALAEPAIVPASEPAPEAPVTRAAITMPAVIQRSSPSLPPI
GAIEPLQGGDAYEFPSKELLQEPPQGQGFFMTQEQLEQNAGLLESVLEDFGVKGEIIHVRPGPVVTLYEF
EPAPGVKSSRVIGLADDIARSMSALSARVAVVPGRNVIGIELPNATRETVYFRELIESGDFQKTGCKLAL
CLGKTIGGEPVIAELAKMPHLLVAGTTGSGKSVAINTMILSLLYRLKPEECRLIMVDPKMLELSVYDGIP
HLLTPVVTDPKKAVMALKWAVREMEDRYRKMSRLGVRNIDGYNQRAAAAREKGAPILATVQTGFEKGTGE
PLFEQQEMDLSPMPYIVVIVDEMADLMMVAGKEIEGAIQRLAQMARAAGIHLIMATQRPSVDVITGTIKA
NFPTRISFQVTSKIDSRTILGEQGAEQLLGQGDMLHMAGGGRIARVHGPFVSDQEVEHVVAHLKTQGRPE
YLETVTADEEEEEVEEDQGAVFDKSAIAAEDGNELYDQAVKVVLRDKKCSTSYIQRRLGIGYNRAASLVE
RMEKDGLVGPANHVGKREIIYGNRDNPPKPESDDLD
MRIPRTNFSPAALYDANHADDYEDPHPAAQGAAHVPAAPEAAAHDHLFEAPEAPRRAPGHRDEETGYAGR
AARLYGHGSAYAPAEVTVSTRDPLPTLAEITGLSGEPGWESHFFLSPNVRFTRTPERELMKRHPPAPEES
RIEADEAAAEASDAETVMDVVPAEPAPSVVETELPSYSPSELLRVLTQQLPSWSAARSQAPEASVTKPAI
TESVAVAEEGPATSETTALPVTDEVPVVPHALPVANLAPESAAVEEDVPHQADARLAYLSDFAFFEFMPL
EVAAVPPTVTEPVKEAARIPAPIAAAPKVSPRKIVAAMPVEIRPQPPTAISSLFRVVECRRPEPATAEPV
TAAPQDIAAEPAAAEAAALPAHQFVETPAPALAEPAIVPASEPAPEAPVTRAAITMPAVIQRSSPSLPPI
GAIEPLQGGDAYEFPSKELLQEPPQGQGFFMTQEQLEQNAGLLESVLEDFGVKGEIIHVRPGPVVTLYEF
EPAPGVKSSRVIGLADDIARSMSALSARVAVVPGRNVIGIELPNATRETVYFRELIESGDFQKTGCKLAL
CLGKTIGGEPVIAELAKMPHLLVAGTTGSGKSVAINTMILSLLYRLKPEECRLIMVDPKMLELSVYDGIP
HLLTPVVTDPKKAVMALKWAVREMEDRYRKMSRLGVRNIDGYNQRAAAAREKGAPILATVQTGFEKGTGE
PLFEQQEMDLSPMPYIVVIVDEMADLMMVAGKEIEGAIQRLAQMARAAGIHLIMATQRPSVDVITGTIKA
NFPTRISFQVTSKIDSRTILGEQGAEQLLGQGDMLHMAGGGRIARVHGPFVSDQEVEHVVAHLKTQGRPE
YLETVTADEEEEEVEEDQGAVFDKSAIAAEDGNELYDQAVKVVLRDKKCSTSYIQRRLGIGYNRAASLVE
RMEKDGLVGPANHVGKREIIYGNRDNPPKPESDDLD
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
Host bacterium
| ID | 3361 | GenBank | NZ_CP019586 |
| Plasmid name | pSymB | Incompatibility group | - |
| Plasmid size | 1639840 bp | Coordinate of oriT [Strand] | 695803..695831 [+] |
| Host baterium | Sinorhizobium meliloti strain CCMM B554 (FSM-MA) |
Cargo genes
| Drug resistance gene | - |
| Virulence gene | htpB |
| Metal resistance gene | actP |
| Degradation gene | - |
| Symbiosis gene | - |
| Anti-CRISPR | AcrIIA7 |