Detailed information of oriT
oriT
The information of the oriT region
| oriTDB ID | 102772 |
| Name | oriT_pRphaN931c |
| Organism | Rhizobium phaseoli strain N931 |
| Sequence Completeness | - |
| NCBI accession of oriT (coordinates [strand]) | NZ_CP013555 (230058..230086 [+], 29 nt) |
| oriT length | 29 nt |
| IRs (inverted repeats) | 14..19, 24..29 (CGTCGC..GCGACG) |
| Location of nic site | _ |
| Conserved sequence flanking the nic site |
_ |
| Note | Predicted by oriTfinder 2.0 |
oriT sequence
Download Length: 29 nt
>oriT_pRphaN931c
AGGGCGCAATATACGTCGCTGTCGCGACG
AGGGCGCAATATACGTCGCTGTCGCGACG
Visualization of oriT structure
oriT secondary structure
Predicted by RNAfold.
Download structure file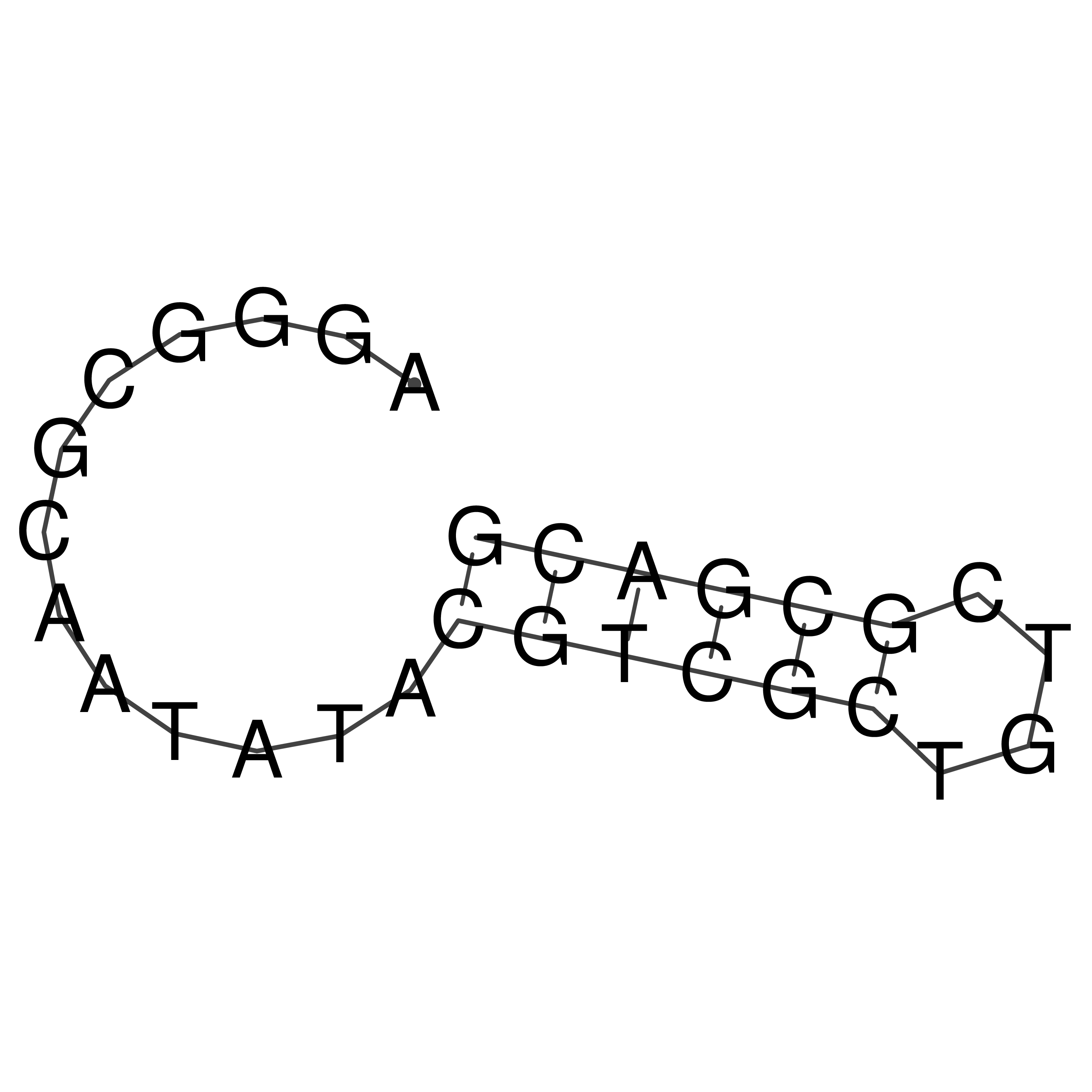
Relaxase
| ID | 2045 | GenBank | WP_046977193 |
| Name | traA_AMC84_RS25575_pRphaN931c |
UniProt ID | A0A192TMB6 |
| Length | 1560 a.a. | PDB ID | |
| Note | Predicted by oriTfinder 2.0 | ||
Relaxase protein sequence
Download Length: 1560 a.a. Molecular weight: 172207.61 Da Isoelectric Point: 6.9611
>WP_046977193.1 MULTISPECIES: Ti-type conjugative transfer relaxase TraA [Rhizobium]
MAIMFVRAQVISRGSGRSIVSAAAYRHRARMMDEQAGTSFSYRGGAGELMYEELALPDEIPDWLRSAISG
QSVSKASEVFWNAVDAFETRADAQLARELIIALPEELTRAENITLVREFVRDNLTSKGMIADWVYHDKDG
NPHIHLMTTLRPLTEEGFGAKKVPVLGEDGKPLRVVTPDRPNGKIVYKVWAGDKETMKAWKIAWAETANR
HLALAGHDIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGRELHFAPADLARRQEMADRLLSEPELLLKQ
LGNERSTFDEREIAKALHRYVDDPVDFANIRVRLMASDQLVILKPQEIEAETGKVSEPAMFTTREMLRIE
YDMAQSARVLSERRGFGVSERNVKVAIESVESGDPKTPFRLDAEQVDAVRHVTGDSGIAAVVGLAGAGKS
TLLAAARLAWEGEGHRVIGAALAGKAAEGLQDSSGIKSRTLASWELAWANGRDTLHRGDVLVIDEAGMVA
SQQMARVLKIAEEAEVKVVLVGDAMQLQPIQAGAAFRAITERIGFAELAGVRRQREAWARNASRLFARGE
VEKGLDAYAQQGHLVEAGTREETIDRIVVDWTEARKHAIGRSISEGRDGRLRGDELLVLAHTNDDVRKLN
EALREVMAGDNALGESRSFRTERGARKFAAGDRIIFLENARFLEPRAKHSGPQYVKNGMLGTVVSTGDKR
GGPLLSVLLDNGNKVVFGEDSYRNVDHGYAATIHKSQGATVDRTFVLATGMMDQHLTYVSMTRHRDRVDL
YAAIEDFEAKPEWGRKAGVDHAAGVTGELVETGEAKFRPDDEDADDSPYADIRTDGGAVHRLWGVSLPKA
LEEASIMEGDTVTLRKDGVERVKVQIAVVDEKTGHKHYEEREVDRNVWTASQVETASARQERIERESHRP
ELFNLLVERLSRSGAKTTTLDFESEASYRAHANDFARRRGLDHLSLAAAEMEESLTRRWAWIAAKREQVE
KLWERASVALGFAIERERRVAYNEERSQTMVEATSSDARTASHSVSGASADETRYLIPPATSFVSSVEED
ARLAQLASPAWTEREVILRPLLEKIYRDPDAALVSLNALASDIGVAARRLADDLAAAPGRLGRLRGSELI
VDGRAAREERNLAVAAVKELLPMARAHATEFRRNAERFDLREQTRRAHMSLSIPALSERAMARLMEIEAV
RRQGGDDAYKSAFALAAEDRSVVQEIKAVSEALTARFGWSAFSAKADAIAERNIVERMPEDLTDERRGKL
TRLFEAVRRFAEEQHLAERRDRSKVVAGASVDLETEKGVGKENVPIPPMLAAVTEFKVPVDDEARSRALS
APLYRQQRVALANAATTIWRDPAEVVGKIEELLQKGFAADRIGAAVANDPAAYAALRGSDRLVDRMLASG
RERKEAVAAVPEAAARLRALGAAYANALNSERQAITEERRRMGVAIPALSKAAEEALARLTAEARKDSRG
LRVSAVPLDPGIGREFAAVSRALDERFGRNAIVRGEKDLVSRLPPAQRRAFEAMQERLKVLQQTVRLQSS
EQITAERRQRAASRARGINL
MAIMFVRAQVISRGSGRSIVSAAAYRHRARMMDEQAGTSFSYRGGAGELMYEELALPDEIPDWLRSAISG
QSVSKASEVFWNAVDAFETRADAQLARELIIALPEELTRAENITLVREFVRDNLTSKGMIADWVYHDKDG
NPHIHLMTTLRPLTEEGFGAKKVPVLGEDGKPLRVVTPDRPNGKIVYKVWAGDKETMKAWKIAWAETANR
HLALAGHDIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGRELHFAPADLARRQEMADRLLSEPELLLKQ
LGNERSTFDEREIAKALHRYVDDPVDFANIRVRLMASDQLVILKPQEIEAETGKVSEPAMFTTREMLRIE
YDMAQSARVLSERRGFGVSERNVKVAIESVESGDPKTPFRLDAEQVDAVRHVTGDSGIAAVVGLAGAGKS
TLLAAARLAWEGEGHRVIGAALAGKAAEGLQDSSGIKSRTLASWELAWANGRDTLHRGDVLVIDEAGMVA
SQQMARVLKIAEEAEVKVVLVGDAMQLQPIQAGAAFRAITERIGFAELAGVRRQREAWARNASRLFARGE
VEKGLDAYAQQGHLVEAGTREETIDRIVVDWTEARKHAIGRSISEGRDGRLRGDELLVLAHTNDDVRKLN
EALREVMAGDNALGESRSFRTERGARKFAAGDRIIFLENARFLEPRAKHSGPQYVKNGMLGTVVSTGDKR
GGPLLSVLLDNGNKVVFGEDSYRNVDHGYAATIHKSQGATVDRTFVLATGMMDQHLTYVSMTRHRDRVDL
YAAIEDFEAKPEWGRKAGVDHAAGVTGELVETGEAKFRPDDEDADDSPYADIRTDGGAVHRLWGVSLPKA
LEEASIMEGDTVTLRKDGVERVKVQIAVVDEKTGHKHYEEREVDRNVWTASQVETASARQERIERESHRP
ELFNLLVERLSRSGAKTTTLDFESEASYRAHANDFARRRGLDHLSLAAAEMEESLTRRWAWIAAKREQVE
KLWERASVALGFAIERERRVAYNEERSQTMVEATSSDARTASHSVSGASADETRYLIPPATSFVSSVEED
ARLAQLASPAWTEREVILRPLLEKIYRDPDAALVSLNALASDIGVAARRLADDLAAAPGRLGRLRGSELI
VDGRAAREERNLAVAAVKELLPMARAHATEFRRNAERFDLREQTRRAHMSLSIPALSERAMARLMEIEAV
RRQGGDDAYKSAFALAAEDRSVVQEIKAVSEALTARFGWSAFSAKADAIAERNIVERMPEDLTDERRGKL
TRLFEAVRRFAEEQHLAERRDRSKVVAGASVDLETEKGVGKENVPIPPMLAAVTEFKVPVDDEARSRALS
APLYRQQRVALANAATTIWRDPAEVVGKIEELLQKGFAADRIGAAVANDPAAYAALRGSDRLVDRMLASG
RERKEAVAAVPEAAARLRALGAAYANALNSERQAITEERRRMGVAIPALSKAAEEALARLTAEARKDSRG
LRVSAVPLDPGIGREFAAVSRALDERFGRNAIVRGEKDLVSRLPPAQRRAFEAMQERLKVLQQTVRLQSS
EQITAERRQRAASRARGINL
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4CP
| ID | 1700 | GenBank | WP_046977192 |
| Name | traG_AMC84_RS25560_pRphaN931c |
UniProt ID | _ |
| Length | 639 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 639 a.a. Molecular weight: 70708.95 Da Isoelectric Point: 9.2487
>WP_046977192.1 MULTISPECIES: Ti-type conjugative transfer system protein TraG [Rhizobium]
MGLRGKPHPSLLLVLAPIAVTTITIYIVGWRWPGLAVGMSGRMEYWFLRAAPVLPLMFGPLAGLLTVWAL
PLHRRRPVAMASLLCFLGIAAYYALREFGRLAPTVQARVVPWDRALSYLDMVAVIAAVAGFMAVAVSARI
SVVVPDEIKRARRGIFGDADWLPMAAAGKLFPPDGEIVVGERYRVDKEIIHALPFDVNDRSTWGQGGKAP
LLTYRQDFDSTHMLFFAGSGGYKTTSNVVPTALIYTGPMICLDPSTEVAPMVVEHRTNALGREVMVLDPT
NPIMGFNVLDGIEASKQKEEDIVGIAHMLLSESLRFESSTGSYFQNQAHNLLTGLLAHVMLSPEYEGRRS
LRSLRQIVSEPEPSVLAMLRDIQEHSGSAFIRETLGVFTNMTEQTFSGVYSTASKDTQWLSLDSYAALVC
GNAFKSSDIVSGKKDVFLNISASILRSYPGIARVIIGSLINAMVQADGAFQRRALFMLDEVDLLGYMRVL
EEARDRGRKYGISMMLMYQSVGQLERHFGKDGATSWIDGCAFASYAAIKALDTARNLSAQCGEMTVEVKG
SSRNIGWDTKNNASRRSENVNFQRRPLIMPHEITQSMRKDEQIIIVQGHSPIRCGRAIYFRRKEMDQAAK
VNRFVKPVL
MGLRGKPHPSLLLVLAPIAVTTITIYIVGWRWPGLAVGMSGRMEYWFLRAAPVLPLMFGPLAGLLTVWAL
PLHRRRPVAMASLLCFLGIAAYYALREFGRLAPTVQARVVPWDRALSYLDMVAVIAAVAGFMAVAVSARI
SVVVPDEIKRARRGIFGDADWLPMAAAGKLFPPDGEIVVGERYRVDKEIIHALPFDVNDRSTWGQGGKAP
LLTYRQDFDSTHMLFFAGSGGYKTTSNVVPTALIYTGPMICLDPSTEVAPMVVEHRTNALGREVMVLDPT
NPIMGFNVLDGIEASKQKEEDIVGIAHMLLSESLRFESSTGSYFQNQAHNLLTGLLAHVMLSPEYEGRRS
LRSLRQIVSEPEPSVLAMLRDIQEHSGSAFIRETLGVFTNMTEQTFSGVYSTASKDTQWLSLDSYAALVC
GNAFKSSDIVSGKKDVFLNISASILRSYPGIARVIIGSLINAMVQADGAFQRRALFMLDEVDLLGYMRVL
EEARDRGRKYGISMMLMYQSVGQLERHFGKDGATSWIDGCAFASYAAIKALDTARNLSAQCGEMTVEVKG
SSRNIGWDTKNNASRRSENVNFQRRPLIMPHEITQSMRKDEQIIIVQGHSPIRCGRAIYFRRKEMDQAAK
VNRFVKPVL
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4SS
T4SS were predicted by using oriTfinder2.
Region 1: 209350..218929
| Locus tag | Coordinates | Strand | Size (bp) | Protein ID | Product | Description |
|---|---|---|---|---|---|---|
| AMC84_RS34505 | 205838..206064 | - | 227 | Protein_183 | chaperonin GroEL | - |
| AMC84_RS25430 (AMC84_PC00167) | 206358..207278 | + | 921 | WP_016737442 | zincin-like metallopeptidase domain-containing protein | - |
| AMC84_RS25435 | 207389..207571 | - | 183 | WP_016737443 | hypothetical protein | - |
| AMC84_RS25440 (AMC84_PC00168) | 208340..208711 | - | 372 | WP_007636193 | hypothetical protein | - |
| AMC84_RS25445 (AMC84_PC00169) | 208810..209346 | + | 537 | WP_016737444 | hypothetical protein | - |
| AMC84_RS25450 (AMC84_PC00170) | 209350..210018 | + | 669 | WP_016737445 | transglycosylase SLT domain-containing protein | virB1 |
| AMC84_RS25455 (AMC84_PC00171) | 210015..210314 | + | 300 | WP_007636189 | TrbC/VirB2 family protein | virB2 |
| AMC84_RS25460 (AMC84_PC00172) | 210320..210658 | + | 339 | WP_011053369 | type IV secretion system protein VirB3 | virB3 |
| AMC84_RS25465 (AMC84_PC00173) | 210651..213017 | + | 2367 | WP_046977188 | VirB4 family type IV secretion system protein | virb4 |
| AMC84_RS25470 (AMC84_PC00174) | 213014..213715 | + | 702 | WP_016737448 | P-type DNA transfer protein VirB5 | virB5 |
| AMC84_RS25475 (AMC84_PC00175) | 213712..213927 | + | 216 | WP_016737449 | EexN family lipoprotein | - |
| AMC84_RS25480 (AMC84_PC00176) | 213930..214862 | + | 933 | WP_046977189 | type IV secretion system protein | virB6 |
| AMC84_RS34510 | 214904..215185 | + | 282 | WP_016737561 | hypothetical protein | - |
| AMC84_RS25485 (AMC84_PC00177) | 215187..215858 | + | 672 | WP_046977190 | virB8 family protein | virB8 |
| AMC84_RS25490 (AMC84_PC00178) | 215855..216712 | + | 858 | WP_016737451 | P-type conjugative transfer protein VirB9 | virB9 |
| AMC84_RS25495 (AMC84_PC00179) | 216721..217893 | + | 1173 | WP_016737452 | type IV secretion system protein VirB10 | virB10 |
| AMC84_RS25500 (AMC84_PC00180) | 217901..218929 | + | 1029 | WP_046977191 | P-type DNA transfer ATPase VirB11 | virB11 |
| AMC84_RS25505 (AMC84_PC00181) | 218973..219551 | - | 579 | WP_016737454 | PIN domain-containing protein | - |
| AMC84_RS25510 (AMC84_PC00182) | 219541..219987 | - | 447 | WP_029532409 | hypothetical protein | - |
| AMC84_RS25515 (AMC84_PC00184) | 220497..221687 | - | 1191 | WP_016737456 | DUF1173 domain-containing protein | - |
| AMC84_RS33685 | 221998..222257 | + | 260 | Protein_203 | toprim domain-containing protein | - |
| AMC84_RS25520 | 222580..223520 | + | 941 | Protein_204 | DUF2493 domain-containing protein | - |
| AMC84_RS25525 (AMC84_PC00187) | 223605..223871 | + | 267 | WP_004676093 | hypothetical protein | - |
Host bacterium
| ID | 3215 | GenBank | NZ_CP013555 |
| Plasmid name | pRphaN931c | Incompatibility group | - |
| Plasmid size | 453545 bp | Coordinate of oriT [Strand] | 230058..230086 [+] |
| Host baterium | Rhizobium phaseoli strain N931 |
Cargo genes
| Drug resistance gene | - |
| Virulence gene | hsiC1/vipB |
| Metal resistance gene | - |
| Degradation gene | - |
| Symbiosis gene | nifX, nifN, nifE, nifK, nifD, nifH, nifS, nifW, fixA, fixB, fixC, fixX, nifA, nifB, nifZ, nifT, nodD, nodJ, nodI, nodS, nodC, fixO, fixN, mLTONO_5203, nodA |
| Anti-CRISPR | - |