Detailed information of oriT
oriT
The information of the oriT region
| oriTDB ID | 102771 |
| Name | oriT_pRphaR630d |
| Organism | Rhizobium phaseoli strain R630 |
| Sequence Completeness | - |
| NCBI accession of oriT (coordinates [strand]) | NZ_CP013541 (1025647..1025675 [-], 29 nt) |
| oriT length | 29 nt |
| IRs (inverted repeats) | 14..19, 24..29 (CGTCGC..GCGACG) |
| Location of nic site | _ |
| Conserved sequence flanking the nic site |
_ |
| Note | Predicted by oriTfinder 2.0 |
oriT sequence
Download Length: 29 nt
>oriT_pRphaR630d
AGGGCGCAATATACGTCGCTGCCGCGACG
AGGGCGCAATATACGTCGCTGCCGCGACG
Visualization of oriT structure
oriT secondary structure
Predicted by RNAfold.
Download structure file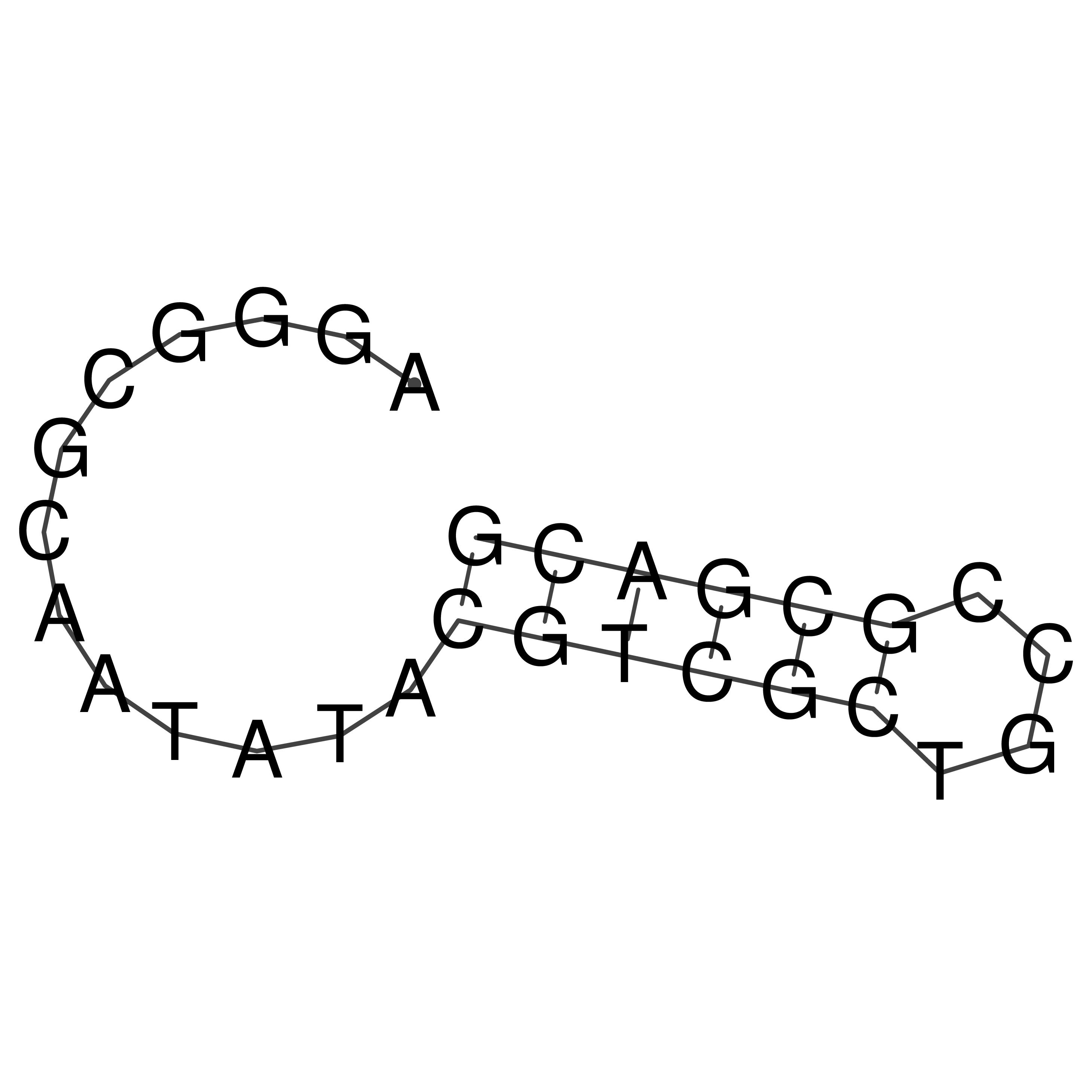
Relaxase
| ID | 2044 | GenBank | WP_064829747 |
| Name | traA_AMC87_RS31375_pRphaR630d |
UniProt ID | _ |
| Length | 1543 a.a. | PDB ID | |
| Note | Predicted by oriTfinder 2.0 | ||
Relaxase protein sequence
Download Length: 1543 a.a. Molecular weight: 171189.72 Da Isoelectric Point: 6.8342
>WP_064829747.1 Ti-type conjugative transfer relaxase TraA [Rhizobium phaseoli]
MAIMFVRAQVISRGAGRSIVSAAAYRHRARMMDEQAGISFSYRGGASELMHEELALPEQIPTWLREAIAG
QPIAKASEALWNAVDAFEKRADAQLARELIIALPEELTRAENIALVREFVRDNLTSKGMIADWVYHDKDG
NPHIHLMTTLRPLTEEGFGPKKVAVLGEDGKPLRVVTPDRSNGRIVYKVWAGDKETMKAWKVAWAETANR
HLALAGHEIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGRELFFAPADLARRQEMADRLLAEPELLLKQ
LGNERSTFDEKDIAKALHRYVDDPVEFANIRARLMASDELVMLKPQEMDADTGKVSEPAVFTTRDMLRIE
YHMAESARRLSNRSGYAVSRKHVAAAIERIESEDPKNLFRLDAEQVDAIRHVTADSGIAAVVGLAGAGKS
TLLAAARLAWESEGRRVIGAALAGKAAEGLEESSGIKSRTLASWELTWANGRDTLHRDDVLVIDEAGMVS
SQQMARVLKIAEEAEIKVVLVGDAMQLQPIQAGAAFRAITERIGFAELAGVRRQRQEWARDASRLLARGE
VERGLDAYARQGHLVEAGTREEAINRIVVDWTEARKQAIDRSTSEGRDGHLRGDELLVLAHTNADVKRLN
AALREVMKAEQALSDSRTFRTARGAREFAVGDRIIFLENARFLEPRARHSGPKYVKNGMLGTVVATGDKR
GDPLMSVLLDNGRNVVFSEDSYRNVDHGYASTIHKSQGATVDRTFVLATGMMDRHLTYVSMTRHRDRVDL
YAAKEDFAARPEWGHKARVDHAAGVTGELVETGEAKFRPDDEDADDSPYADIRTDDGTVHRLWGVSLPKA
LEEAGISEGDTITLRKDGVERVKVQIAVVDEATGQKRYDEREVDRNVWRAKQIETAEARQERIERERHRP
DVFGRLVERLARSGAKTTTLDFESEAGYRAHADDFARRRGLDHLSLAAAEMEEGVSRRLAWIAEKRGQIA
KLWERASVALGLAIERERRVAYNEERSETMIGAISSEERYLIPPATDFRRSLDEDARLAQLSSPAWKERE
AILRPLLETIYRDPDAALVRLNALASDTGTEPRGLADNLAVAPDRLGRLRGSELIVEGRAARDERDAAMA
ALEELLPLVRGHATEFRRNAEPFELREQARRASMSLSVPALSEQAMARLMEIEAVRTQGGDDAYKTAFAL
AAEDRSVVQEVKAVSEALTARFGWSAFTAKADAMAERNMVERMPEDLSAGRREELIRLFEALKRFAEEQH
LAERRDRSKIVAAASAVPGAAPGKQTVTVLPMLAAVTEFKTSVDDEARSRAIAAPLYRQQRSALAEAARM
IWRDPAATVDNIESLLEKGFAADRIAAAVTNDPAAYGALRGSGRLMDRMLASGRERKYAVQAVPEAAAHL
RSLGSAYENVLDAERQAIAEERRRMAVAIPGLSKAAEEVLMRLTTEAKNNGRTRNAAAVSLDPSIHREFA
AVSRALDERFGRNAIVRGDTDLIDRMPPAQRAAFAAMQEKLKVLQQTVRWESSEKIVSELRNRTLNRSRG
IEL
MAIMFVRAQVISRGAGRSIVSAAAYRHRARMMDEQAGISFSYRGGASELMHEELALPEQIPTWLREAIAG
QPIAKASEALWNAVDAFEKRADAQLARELIIALPEELTRAENIALVREFVRDNLTSKGMIADWVYHDKDG
NPHIHLMTTLRPLTEEGFGPKKVAVLGEDGKPLRVVTPDRSNGRIVYKVWAGDKETMKAWKVAWAETANR
HLALAGHEIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGRELFFAPADLARRQEMADRLLAEPELLLKQ
LGNERSTFDEKDIAKALHRYVDDPVEFANIRARLMASDELVMLKPQEMDADTGKVSEPAVFTTRDMLRIE
YHMAESARRLSNRSGYAVSRKHVAAAIERIESEDPKNLFRLDAEQVDAIRHVTADSGIAAVVGLAGAGKS
TLLAAARLAWESEGRRVIGAALAGKAAEGLEESSGIKSRTLASWELTWANGRDTLHRDDVLVIDEAGMVS
SQQMARVLKIAEEAEIKVVLVGDAMQLQPIQAGAAFRAITERIGFAELAGVRRQRQEWARDASRLLARGE
VERGLDAYARQGHLVEAGTREEAINRIVVDWTEARKQAIDRSTSEGRDGHLRGDELLVLAHTNADVKRLN
AALREVMKAEQALSDSRTFRTARGAREFAVGDRIIFLENARFLEPRARHSGPKYVKNGMLGTVVATGDKR
GDPLMSVLLDNGRNVVFSEDSYRNVDHGYASTIHKSQGATVDRTFVLATGMMDRHLTYVSMTRHRDRVDL
YAAKEDFAARPEWGHKARVDHAAGVTGELVETGEAKFRPDDEDADDSPYADIRTDDGTVHRLWGVSLPKA
LEEAGISEGDTITLRKDGVERVKVQIAVVDEATGQKRYDEREVDRNVWRAKQIETAEARQERIERERHRP
DVFGRLVERLARSGAKTTTLDFESEAGYRAHADDFARRRGLDHLSLAAAEMEEGVSRRLAWIAEKRGQIA
KLWERASVALGLAIERERRVAYNEERSETMIGAISSEERYLIPPATDFRRSLDEDARLAQLSSPAWKERE
AILRPLLETIYRDPDAALVRLNALASDTGTEPRGLADNLAVAPDRLGRLRGSELIVEGRAARDERDAAMA
ALEELLPLVRGHATEFRRNAEPFELREQARRASMSLSVPALSEQAMARLMEIEAVRTQGGDDAYKTAFAL
AAEDRSVVQEVKAVSEALTARFGWSAFTAKADAMAERNMVERMPEDLSAGRREELIRLFEALKRFAEEQH
LAERRDRSKIVAAASAVPGAAPGKQTVTVLPMLAAVTEFKTSVDDEARSRAIAAPLYRQQRSALAEAARM
IWRDPAATVDNIESLLEKGFAADRIAAAVTNDPAAYGALRGSGRLMDRMLASGRERKYAVQAVPEAAAHL
RSLGSAYENVLDAERQAIAEERRRMAVAIPGLSKAAEEVLMRLTTEAKNNGRTRNAAAVSLDPSIHREFA
AVSRALDERFGRNAIVRGDTDLIDRMPPAQRAAFAAMQEKLKVLQQTVRWESSEKIVSELRNRTLNRSRG
IEL
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4CP
| ID | 1699 | GenBank | WP_064829750 |
| Name | traG_AMC87_RS31390_pRphaR630d |
UniProt ID | _ |
| Length | 639 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 639 a.a. Molecular weight: 70407.29 Da Isoelectric Point: 9.3707
>WP_064829750.1 Ti-type conjugative transfer system protein TraG [Rhizobium phaseoli]
MIARGKPHPSLLFVFAPVVVTAIAVYIAGWRWPGLAAGMPGRMEYWFLRAAPVPALLFGPLAGLLTVWAL
PLHRRRPVAMTSLLCYLGVSASYAMREFARLGPSVQTGVITWDRALSYLDMVAVLGAVAGFLAVAVSARI
SVVVPDEINRARRGTFGDADWLSMAAAAKLFPSDGEIVVGERYRVDKEIVHQLPFDANDRGTWGQGGKAP
LLTYKQDFDSTHMLFFAGSGGYKTTSNVVPTALRYTGPLICLDPSTEVAPMVVEHRTHALGREVMVLDPT
NPIMGFNVLDGIETSRQKEEDIVGIAHMLLSESVRFESSTGSYFQSQAHNLLTGLLAHVMLSPEYAGRRN
LRSLREIVSEPEPSVLAMLRDIQENSQSDFIRETLGVFTNMTEQTFSGVYSTASKDTQWLSLDSYAALVC
GKAFKPSDIVSGRKDVFLNIPASILRSYPGIGRVIIGSLINAMMQADGAFRRRALFMLDEVDLLGYMRVL
EEARDRGRKYGVSMMLMYQAVGQLERHFGKDGATSWIEGCAFASYAAVKALDTARTVSAQCGEMTVEVKG
SSRNLGWNSRNGGTRKSESVSFQRRPLIMPHEITQSMRKDEQIIIVQGHSPIRCGRAIYFRRKEMDGVAK
ANRFVKPVP
MIARGKPHPSLLFVFAPVVVTAIAVYIAGWRWPGLAAGMPGRMEYWFLRAAPVPALLFGPLAGLLTVWAL
PLHRRRPVAMTSLLCYLGVSASYAMREFARLGPSVQTGVITWDRALSYLDMVAVLGAVAGFLAVAVSARI
SVVVPDEINRARRGTFGDADWLSMAAAAKLFPSDGEIVVGERYRVDKEIVHQLPFDANDRGTWGQGGKAP
LLTYKQDFDSTHMLFFAGSGGYKTTSNVVPTALRYTGPLICLDPSTEVAPMVVEHRTHALGREVMVLDPT
NPIMGFNVLDGIETSRQKEEDIVGIAHMLLSESVRFESSTGSYFQSQAHNLLTGLLAHVMLSPEYAGRRN
LRSLREIVSEPEPSVLAMLRDIQENSQSDFIRETLGVFTNMTEQTFSGVYSTASKDTQWLSLDSYAALVC
GKAFKPSDIVSGRKDVFLNIPASILRSYPGIGRVIIGSLINAMMQADGAFRRRALFMLDEVDLLGYMRVL
EEARDRGRKYGVSMMLMYQAVGQLERHFGKDGATSWIEGCAFASYAAVKALDTARTVSAQCGEMTVEVKG
SSRNLGWNSRNGGTRKSESVSFQRRPLIMPHEITQSMRKDEQIIIVQGHSPIRCGRAIYFRRKEMDGVAK
ANRFVKPVP
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4SS
T4SS were predicted by using oriTfinder2.
Region 1: 1037546..1047102
| Locus tag | Coordinates | Strand | Size (bp) | Protein ID | Product | Description |
|---|---|---|---|---|---|---|
| AMC87_RS31430 (AMC87_PD00993) | 1033137..1033319 | + | 183 | WP_064829756 | hypothetical protein | - |
| AMC87_RS31435 (AMC87_PD00994) | 1033452..1034489 | - | 1038 | WP_064829757 | toprim domain-containing protein | - |
| AMC87_RS31440 (AMC87_PD00995) | 1034852..1036042 | + | 1191 | WP_064829758 | DUF1173 domain-containing protein | - |
| AMC87_RS31445 (AMC87_PD00996) | 1036468..1037061 | + | 594 | WP_064829759 | DUF433 domain-containing protein | - |
| AMC87_RS31450 (AMC87_PD00997) | 1037177..1037527 | + | 351 | WP_237358123 | type II toxin-antitoxin system VapC family toxin | - |
| AMC87_RS31455 (AMC87_PD00998) | 1037546..1038541 | - | 996 | WP_064829760 | P-type DNA transfer ATPase VirB11 | virB11 |
| AMC87_RS31460 (AMC87_PD00999) | 1038550..1039725 | - | 1176 | WP_064829761 | type IV secretion system protein VirB10 | virB10 |
| AMC87_RS31465 (AMC87_PD01000) | 1039734..1040588 | - | 855 | WP_064829762 | P-type conjugative transfer protein VirB9 | virB9 |
| AMC87_RS31470 (AMC87_PD01001) | 1040585..1041256 | - | 672 | WP_064829763 | virB8 family protein | virB8 |
| AMC87_RS34455 (AMC87_PD01002) | 1041250..1041537 | - | 288 | WP_012490329 | hypothetical protein | - |
| AMC87_RS31480 (AMC87_PD01003) | 1041578..1042510 | - | 933 | WP_012490330 | type IV secretion system protein | virB6 |
| AMC87_RS31485 (AMC87_PD01004) | 1042513..1042746 | - | 234 | WP_012490331 | EexN family lipoprotein | - |
| AMC87_RS31490 (AMC87_PD01005) | 1042743..1043444 | - | 702 | WP_064829764 | P-type DNA transfer protein VirB5 | virB5 |
| AMC87_RS31495 (AMC87_PD01006) | 1043441..1045807 | - | 2367 | WP_064829765 | VirB4 family type IV secretion system protein | virb4 |
| AMC87_RS31500 (AMC87_PD01007) | 1045800..1046138 | - | 339 | WP_064829766 | type IV secretion system protein VirB3 | virB3 |
| AMC87_RS31505 (AMC87_PD01008) | 1046144..1046443 | - | 300 | WP_016735283 | TrbC/VirB2 family protein | virB2 |
| AMC87_RS31510 (AMC87_PD01009) | 1046440..1047102 | - | 663 | WP_064829767 | transglycosylase SLT domain-containing protein | virB1 |
| AMC87_RS31515 (AMC87_PD01010) | 1047106..1047642 | - | 537 | WP_064829768 | hypothetical protein | - |
| AMC87_RS31520 (AMC87_PD01011) | 1047741..1048112 | + | 372 | WP_064829839 | hypothetical protein | - |
| AMC87_RS31525 (AMC87_PD01012) | 1048465..1049655 | - | 1191 | WP_064829769 | hypothetical protein | - |
| AMC87_RS31530 (AMC87_PD01013) | 1049729..1050385 | - | 657 | WP_064829770 | hypothetical protein | - |
Host bacterium
| ID | 3214 | GenBank | NZ_CP013541 |
| Plasmid name | pRphaR630d | Incompatibility group | - |
| Plasmid size | 1144409 bp | Coordinate of oriT [Strand] | 1025647..1025675 [-] |
| Host baterium | Rhizobium phaseoli strain R630 |
Cargo genes
| Drug resistance gene | - |
| Virulence gene | gmd |
| Metal resistance gene | hupE2 |
| Degradation gene | dxnH, LinG, genH |
| Symbiosis gene | noeL, fixB, fixA |
| Anti-CRISPR | AcrIIA8 |