Detailed information of oriT
oriT
The information of the oriT region
| oriTDB ID | 102770 |
| Name | oriT_pRphaR630c |
| Organism | Rhizobium phaseoli strain R630 |
| Sequence Completeness | - |
| NCBI accession of oriT (coordinates [strand]) | NZ_CP013540 (219515..219543 [+], 29 nt) |
| oriT length | 29 nt |
| IRs (inverted repeats) | 14..19, 24..29 (CGTCGC..GCGACG) |
| Location of nic site | _ |
| Conserved sequence flanking the nic site |
_ |
| Note | Predicted by oriTfinder 2.0 |
oriT sequence
Download Length: 29 nt
>oriT_pRphaR630c
AGGGCGCAATATACGTCGCTGTCGCGACG
AGGGCGCAATATACGTCGCTGTCGCGACG
Visualization of oriT structure
oriT secondary structure
Predicted by RNAfold.
Download structure file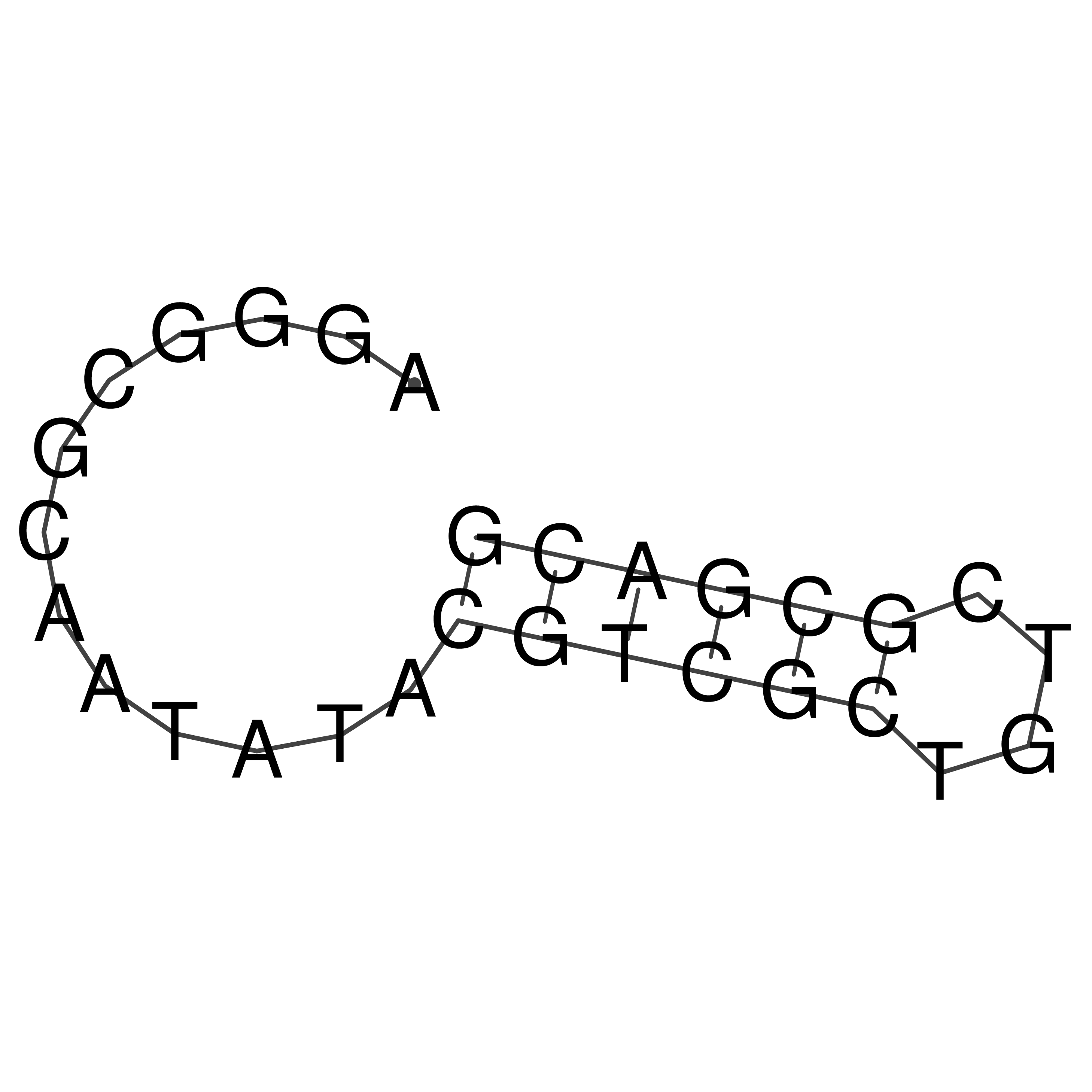
Relaxase
| ID | 2043 | GenBank | WP_046977193 |
| Name | traA_AMC87_RS25695_pRphaR630c |
UniProt ID | A0A192TMB6 |
| Length | 1560 a.a. | PDB ID | |
| Note | Predicted by oriTfinder 2.0 | ||
Relaxase protein sequence
Download Length: 1560 a.a. Molecular weight: 172207.61 Da Isoelectric Point: 6.9611
>WP_046977193.1 MULTISPECIES: Ti-type conjugative transfer relaxase TraA [Rhizobium]
MAIMFVRAQVISRGSGRSIVSAAAYRHRARMMDEQAGTSFSYRGGAGELMYEELALPDEIPDWLRSAISG
QSVSKASEVFWNAVDAFETRADAQLARELIIALPEELTRAENITLVREFVRDNLTSKGMIADWVYHDKDG
NPHIHLMTTLRPLTEEGFGAKKVPVLGEDGKPLRVVTPDRPNGKIVYKVWAGDKETMKAWKIAWAETANR
HLALAGHDIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGRELHFAPADLARRQEMADRLLSEPELLLKQ
LGNERSTFDEREIAKALHRYVDDPVDFANIRVRLMASDQLVILKPQEIEAETGKVSEPAMFTTREMLRIE
YDMAQSARVLSERRGFGVSERNVKVAIESVESGDPKTPFRLDAEQVDAVRHVTGDSGIAAVVGLAGAGKS
TLLAAARLAWEGEGHRVIGAALAGKAAEGLQDSSGIKSRTLASWELAWANGRDTLHRGDVLVIDEAGMVA
SQQMARVLKIAEEAEVKVVLVGDAMQLQPIQAGAAFRAITERIGFAELAGVRRQREAWARNASRLFARGE
VEKGLDAYAQQGHLVEAGTREETIDRIVVDWTEARKHAIGRSISEGRDGRLRGDELLVLAHTNDDVRKLN
EALREVMAGDNALGESRSFRTERGARKFAAGDRIIFLENARFLEPRAKHSGPQYVKNGMLGTVVSTGDKR
GGPLLSVLLDNGNKVVFGEDSYRNVDHGYAATIHKSQGATVDRTFVLATGMMDQHLTYVSMTRHRDRVDL
YAAIEDFEAKPEWGRKAGVDHAAGVTGELVETGEAKFRPDDEDADDSPYADIRTDGGAVHRLWGVSLPKA
LEEASIMEGDTVTLRKDGVERVKVQIAVVDEKTGHKHYEEREVDRNVWTASQVETASARQERIERESHRP
ELFNLLVERLSRSGAKTTTLDFESEASYRAHANDFARRRGLDHLSLAAAEMEESLTRRWAWIAAKREQVE
KLWERASVALGFAIERERRVAYNEERSQTMVEATSSDARTASHSVSGASADETRYLIPPATSFVSSVEED
ARLAQLASPAWTEREVILRPLLEKIYRDPDAALVSLNALASDIGVAARRLADDLAAAPGRLGRLRGSELI
VDGRAAREERNLAVAAVKELLPMARAHATEFRRNAERFDLREQTRRAHMSLSIPALSERAMARLMEIEAV
RRQGGDDAYKSAFALAAEDRSVVQEIKAVSEALTARFGWSAFSAKADAIAERNIVERMPEDLTDERRGKL
TRLFEAVRRFAEEQHLAERRDRSKVVAGASVDLETEKGVGKENVPIPPMLAAVTEFKVPVDDEARSRALS
APLYRQQRVALANAATTIWRDPAEVVGKIEELLQKGFAADRIGAAVANDPAAYAALRGSDRLVDRMLASG
RERKEAVAAVPEAAARLRALGAAYANALNSERQAITEERRRMGVAIPALSKAAEEALARLTAEARKDSRG
LRVSAVPLDPGIGREFAAVSRALDERFGRNAIVRGEKDLVSRLPPAQRRAFEAMQERLKVLQQTVRLQSS
EQITAERRQRAASRARGINL
MAIMFVRAQVISRGSGRSIVSAAAYRHRARMMDEQAGTSFSYRGGAGELMYEELALPDEIPDWLRSAISG
QSVSKASEVFWNAVDAFETRADAQLARELIIALPEELTRAENITLVREFVRDNLTSKGMIADWVYHDKDG
NPHIHLMTTLRPLTEEGFGAKKVPVLGEDGKPLRVVTPDRPNGKIVYKVWAGDKETMKAWKIAWAETANR
HLALAGHDIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGRELHFAPADLARRQEMADRLLSEPELLLKQ
LGNERSTFDEREIAKALHRYVDDPVDFANIRVRLMASDQLVILKPQEIEAETGKVSEPAMFTTREMLRIE
YDMAQSARVLSERRGFGVSERNVKVAIESVESGDPKTPFRLDAEQVDAVRHVTGDSGIAAVVGLAGAGKS
TLLAAARLAWEGEGHRVIGAALAGKAAEGLQDSSGIKSRTLASWELAWANGRDTLHRGDVLVIDEAGMVA
SQQMARVLKIAEEAEVKVVLVGDAMQLQPIQAGAAFRAITERIGFAELAGVRRQREAWARNASRLFARGE
VEKGLDAYAQQGHLVEAGTREETIDRIVVDWTEARKHAIGRSISEGRDGRLRGDELLVLAHTNDDVRKLN
EALREVMAGDNALGESRSFRTERGARKFAAGDRIIFLENARFLEPRAKHSGPQYVKNGMLGTVVSTGDKR
GGPLLSVLLDNGNKVVFGEDSYRNVDHGYAATIHKSQGATVDRTFVLATGMMDQHLTYVSMTRHRDRVDL
YAAIEDFEAKPEWGRKAGVDHAAGVTGELVETGEAKFRPDDEDADDSPYADIRTDGGAVHRLWGVSLPKA
LEEASIMEGDTVTLRKDGVERVKVQIAVVDEKTGHKHYEEREVDRNVWTASQVETASARQERIERESHRP
ELFNLLVERLSRSGAKTTTLDFESEASYRAHANDFARRRGLDHLSLAAAEMEESLTRRWAWIAAKREQVE
KLWERASVALGFAIERERRVAYNEERSQTMVEATSSDARTASHSVSGASADETRYLIPPATSFVSSVEED
ARLAQLASPAWTEREVILRPLLEKIYRDPDAALVSLNALASDIGVAARRLADDLAAAPGRLGRLRGSELI
VDGRAAREERNLAVAAVKELLPMARAHATEFRRNAERFDLREQTRRAHMSLSIPALSERAMARLMEIEAV
RRQGGDDAYKSAFALAAEDRSVVQEIKAVSEALTARFGWSAFSAKADAIAERNIVERMPEDLTDERRGKL
TRLFEAVRRFAEEQHLAERRDRSKVVAGASVDLETEKGVGKENVPIPPMLAAVTEFKVPVDDEARSRALS
APLYRQQRVALANAATTIWRDPAEVVGKIEELLQKGFAADRIGAAVANDPAAYAALRGSDRLVDRMLASG
RERKEAVAAVPEAAARLRALGAAYANALNSERQAITEERRRMGVAIPALSKAAEEALARLTAEARKDSRG
LRVSAVPLDPGIGREFAAVSRALDERFGRNAIVRGEKDLVSRLPPAQRRAFEAMQERLKVLQQTVRLQSS
EQITAERRQRAASRARGINL
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4CP
| ID | 1697 | GenBank | WP_237358108 |
| Name | t4cp2_AMC87_RS24840_pRphaR630c |
UniProt ID | _ |
| Length | 1647 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 1647 a.a. Molecular weight: 180452.62 Da Isoelectric Point: 6.3216
>WP_237358108.1 ATP-binding protein [Rhizobium phaseoli]
MGPEHHKHFSSALTDLLGGPTEGAVAFLRCLPSEQVDALADAEDFAVLGWTVNAVVDKPGYRRITADQAV
EQREDKANAALFLIDPLRAGAGLDGIYNAAREIREPELFKAAQARARKELRGRLGTVNAALKRAERLGRR
RKLTPWQEFDFMVAVGADGERRAIASVGLWPVQGEGTLSTEELDLSVAMADRLLFPSDARTVGERVRSLL
LDNKPEDVANLERFLRPLAGRSPEEAAAAIAERPEFWLGSLKPRFSGEELQKIILSSWRKPNGGMQAWSG
LRLPGEDSLKPTLLLDRDLTPKERAKLTVRWTIEPAQIAAGGVEYRVSILAGEEVLTEQTIAHRDKPHQQ
AVFSLDDFEDLEGTEKFEALVQIAPVAAEGVEAVRSEEFVLEFGVTSDTGTSAGSGQVVRALVEGAAAIK
ERSAFDKAVTGVPGPDRASEDKKGFIIWKGEGGGRAVRVARPLLIRNVEEDWAARRGTPGRWVQKVRADG
APSGAIDFVELQHGACDGEAWRRVCEASRRLAEELGPLGLLGRVKTAGWRRADEYVNAWLAGLESGGPDL
ALHGTVEVKSLSGRTLGLLVTPLHPLRFAWSALYDNVAAHARYEENLESVRLQRALKPLDSANFPFALPG
IDGGRPFLFADVLGFHAVAMTLDGEPEPKGAVAVLGACLGGGTRAVAPSVGTESAYVLAREVRHFLRCHE
GATGDRPDLLNIQAWRPGDGMTVARALGQVLNDGIGDEDQEIESATPLCFTLDLYHPPSSSESGRFLSML
GQRRRSGGGVLEASDRWMTETATRPGGVLVPRLRWSKRPEPVSNESESWAGVRPTHLSMIFDVFEARLEV
RPASDLGRARPLHVYGLTKALERRAFVGHDPEWMVWMPPELSGERAPDGSNLGERLRKMDTAVARLTARA
LGGGAESWPVLVTRLSNDGRQRMDRLHECSDWVITADRNAALEYFDAPHSQRDVYQRFVIDAVPERADLG
SLQLVTSTTNLDAMRDLVDEALDAMGLSGSARNTRFLVNHLKALSGRLAIRLANAQNRAGEMIALALVQA
NCVAAAGADGPWVDLARGFLLPVDEIADFAPIADRTTGEGTNHRADFIHVAVPARGPIEFRFIEVKHRLH
LRSARDPALLEQMLKQTGELRRRWSDWFFGPKITPLDRVTRRSQLARLLRFYADRAARHRLSDRDHSRLL
GEIDALVLKETYIPGAVEFPDIGYVFCPEHRRGTVEPIYASGGEHARFYLFGPGLLPDGDTPYGHANTPS
VPAAVAELAAAEISETSLPAADTISLPTSSDTIEMAPETSSISEGVDVLLGTTPGGEPVEWRVSIKTNPH
LMVAGLPGMGKTTALVNICRQLTQNGVAPIVFSFHDDIDEKLARSLGPLHFTDFTGLGFNPLRVDGVAPT
AYVDVTGTLRDIFASIFPDLGDLQLEELRQAIKQSFEYNGWGRAREKDERPEPPAFRTFFDILRSKQKPN
ANLLARLQELADYGFFDAASDNPSLLAEPRPTIIRVHSTTNSILQNAFSSFVLYSLYKDMFRRGVQSRLT
HAIIFDEAHRAAKLKLIPQFAKECRKYGLSLALASQGAKDFSPALFEAVGSYLMLRVTEADARAFARNAA
STGDQSRITDRLKSLEPYNALFLSTVTNHPRSVRLLS
MGPEHHKHFSSALTDLLGGPTEGAVAFLRCLPSEQVDALADAEDFAVLGWTVNAVVDKPGYRRITADQAV
EQREDKANAALFLIDPLRAGAGLDGIYNAAREIREPELFKAAQARARKELRGRLGTVNAALKRAERLGRR
RKLTPWQEFDFMVAVGADGERRAIASVGLWPVQGEGTLSTEELDLSVAMADRLLFPSDARTVGERVRSLL
LDNKPEDVANLERFLRPLAGRSPEEAAAAIAERPEFWLGSLKPRFSGEELQKIILSSWRKPNGGMQAWSG
LRLPGEDSLKPTLLLDRDLTPKERAKLTVRWTIEPAQIAAGGVEYRVSILAGEEVLTEQTIAHRDKPHQQ
AVFSLDDFEDLEGTEKFEALVQIAPVAAEGVEAVRSEEFVLEFGVTSDTGTSAGSGQVVRALVEGAAAIK
ERSAFDKAVTGVPGPDRASEDKKGFIIWKGEGGGRAVRVARPLLIRNVEEDWAARRGTPGRWVQKVRADG
APSGAIDFVELQHGACDGEAWRRVCEASRRLAEELGPLGLLGRVKTAGWRRADEYVNAWLAGLESGGPDL
ALHGTVEVKSLSGRTLGLLVTPLHPLRFAWSALYDNVAAHARYEENLESVRLQRALKPLDSANFPFALPG
IDGGRPFLFADVLGFHAVAMTLDGEPEPKGAVAVLGACLGGGTRAVAPSVGTESAYVLAREVRHFLRCHE
GATGDRPDLLNIQAWRPGDGMTVARALGQVLNDGIGDEDQEIESATPLCFTLDLYHPPSSSESGRFLSML
GQRRRSGGGVLEASDRWMTETATRPGGVLVPRLRWSKRPEPVSNESESWAGVRPTHLSMIFDVFEARLEV
RPASDLGRARPLHVYGLTKALERRAFVGHDPEWMVWMPPELSGERAPDGSNLGERLRKMDTAVARLTARA
LGGGAESWPVLVTRLSNDGRQRMDRLHECSDWVITADRNAALEYFDAPHSQRDVYQRFVIDAVPERADLG
SLQLVTSTTNLDAMRDLVDEALDAMGLSGSARNTRFLVNHLKALSGRLAIRLANAQNRAGEMIALALVQA
NCVAAAGADGPWVDLARGFLLPVDEIADFAPIADRTTGEGTNHRADFIHVAVPARGPIEFRFIEVKHRLH
LRSARDPALLEQMLKQTGELRRRWSDWFFGPKITPLDRVTRRSQLARLLRFYADRAARHRLSDRDHSRLL
GEIDALVLKETYIPGAVEFPDIGYVFCPEHRRGTVEPIYASGGEHARFYLFGPGLLPDGDTPYGHANTPS
VPAAVAELAAAEISETSLPAADTISLPTSSDTIEMAPETSSISEGVDVLLGTTPGGEPVEWRVSIKTNPH
LMVAGLPGMGKTTALVNICRQLTQNGVAPIVFSFHDDIDEKLARSLGPLHFTDFTGLGFNPLRVDGVAPT
AYVDVTGTLRDIFASIFPDLGDLQLEELRQAIKQSFEYNGWGRAREKDERPEPPAFRTFFDILRSKQKPN
ANLLARLQELADYGFFDAASDNPSLLAEPRPTIIRVHSTTNSILQNAFSSFVLYSLYKDMFRRGVQSRLT
HAIIFDEAHRAAKLKLIPQFAKECRKYGLSLALASQGAKDFSPALFEAVGSYLMLRVTEADARAFARNAA
STGDQSRITDRLKSLEPYNALFLSTVTNHPRSVRLLS
Protein domains
No domain identified.
Protein structure
No available structure.
| ID | 1698 | GenBank | WP_046977192 |
| Name | traG_AMC87_RS25680_pRphaR630c |
UniProt ID | _ |
| Length | 639 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 639 a.a. Molecular weight: 70708.95 Da Isoelectric Point: 9.2487
>WP_046977192.1 MULTISPECIES: Ti-type conjugative transfer system protein TraG [Rhizobium]
MGLRGKPHPSLLLVLAPIAVTTITIYIVGWRWPGLAVGMSGRMEYWFLRAAPVLPLMFGPLAGLLTVWAL
PLHRRRPVAMASLLCFLGIAAYYALREFGRLAPTVQARVVPWDRALSYLDMVAVIAAVAGFMAVAVSARI
SVVVPDEIKRARRGIFGDADWLPMAAAGKLFPPDGEIVVGERYRVDKEIIHALPFDVNDRSTWGQGGKAP
LLTYRQDFDSTHMLFFAGSGGYKTTSNVVPTALIYTGPMICLDPSTEVAPMVVEHRTNALGREVMVLDPT
NPIMGFNVLDGIEASKQKEEDIVGIAHMLLSESLRFESSTGSYFQNQAHNLLTGLLAHVMLSPEYEGRRS
LRSLRQIVSEPEPSVLAMLRDIQEHSGSAFIRETLGVFTNMTEQTFSGVYSTASKDTQWLSLDSYAALVC
GNAFKSSDIVSGKKDVFLNISASILRSYPGIARVIIGSLINAMVQADGAFQRRALFMLDEVDLLGYMRVL
EEARDRGRKYGISMMLMYQSVGQLERHFGKDGATSWIDGCAFASYAAIKALDTARNLSAQCGEMTVEVKG
SSRNIGWDTKNNASRRSENVNFQRRPLIMPHEITQSMRKDEQIIIVQGHSPIRCGRAIYFRRKEMDQAAK
VNRFVKPVL
MGLRGKPHPSLLLVLAPIAVTTITIYIVGWRWPGLAVGMSGRMEYWFLRAAPVLPLMFGPLAGLLTVWAL
PLHRRRPVAMASLLCFLGIAAYYALREFGRLAPTVQARVVPWDRALSYLDMVAVIAAVAGFMAVAVSARI
SVVVPDEIKRARRGIFGDADWLPMAAAGKLFPPDGEIVVGERYRVDKEIIHALPFDVNDRSTWGQGGKAP
LLTYRQDFDSTHMLFFAGSGGYKTTSNVVPTALIYTGPMICLDPSTEVAPMVVEHRTNALGREVMVLDPT
NPIMGFNVLDGIEASKQKEEDIVGIAHMLLSESLRFESSTGSYFQNQAHNLLTGLLAHVMLSPEYEGRRS
LRSLRQIVSEPEPSVLAMLRDIQEHSGSAFIRETLGVFTNMTEQTFSGVYSTASKDTQWLSLDSYAALVC
GNAFKSSDIVSGKKDVFLNISASILRSYPGIARVIIGSLINAMVQADGAFQRRALFMLDEVDLLGYMRVL
EEARDRGRKYGISMMLMYQSVGQLERHFGKDGATSWIDGCAFASYAAIKALDTARNLSAQCGEMTVEVKG
SSRNIGWDTKNNASRRSENVNFQRRPLIMPHEITQSMRKDEQIIIVQGHSPIRCGRAIYFRRKEMDQAAK
VNRFVKPVL
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4SS
T4SS were predicted by using oriTfinder2.
Region 1: 198784..208382
| Locus tag | Coordinates | Strand | Size (bp) | Protein ID | Product | Description |
|---|---|---|---|---|---|---|
| AMC87_RS34245 | 195559..195785 | - | 227 | Protein_174 | chaperonin GroEL | - |
| AMC87_RS25555 (AMC87_PC00172) | 196080..197000 | + | 921 | WP_004673402 | zincin-like metallopeptidase domain-containing protein | - |
| AMC87_RS25560 (AMC87_PC00174) | 197774..198145 | - | 372 | WP_042120136 | hypothetical protein | - |
| AMC87_RS25565 (AMC87_PC00175) | 198244..198780 | + | 537 | WP_011053366 | hypothetical protein | - |
| AMC87_RS25570 (AMC87_PC00176) | 198784..199452 | + | 669 | WP_064820013 | lytic transglycosylase domain-containing protein | virB1 |
| AMC87_RS25575 (AMC87_PC00177) | 199449..199748 | + | 300 | WP_007636189 | TrbC/VirB2 family protein | virB2 |
| AMC87_RS25580 (AMC87_PC00178) | 199754..200092 | + | 339 | WP_011053369 | type IV secretion system protein VirB3 | virB3 |
| AMC87_RS25585 (AMC87_PC00179) | 200085..202451 | + | 2367 | WP_064820014 | VirB4 family type IV secretion system protein | virb4 |
| AMC87_RS25590 (AMC87_PC00180) | 202448..203149 | + | 702 | WP_011053371 | P-type DNA transfer protein VirB5 | virB5 |
| AMC87_RS25595 (AMC87_PC00181) | 203146..203379 | + | 234 | WP_008537008 | EexN family lipoprotein | - |
| AMC87_RS25600 (AMC87_PC00182) | 203382..204314 | + | 933 | WP_064820015 | type IV secretion system protein | virB6 |
| AMC87_RS34250 (AMC87_PC00183) | 204356..204637 | + | 282 | WP_081278376 | hypothetical protein | - |
| AMC87_RS25605 (AMC87_PC00184) | 204639..205310 | + | 672 | WP_064820016 | virB8 family protein | virB8 |
| AMC87_RS25610 (AMC87_PC00185) | 205307..206164 | + | 858 | WP_064820017 | P-type conjugative transfer protein VirB9 | virB9 |
| AMC87_RS25615 (AMC87_PC00186) | 206173..207345 | + | 1173 | WP_064820018 | type IV secretion system protein VirB10 | virB10 |
| AMC87_RS25620 (AMC87_PC00187) | 207354..208382 | + | 1029 | WP_064820019 | P-type DNA transfer ATPase VirB11 | virB11 |
| AMC87_RS25625 (AMC87_PC00188) | 208426..209004 | - | 579 | WP_064820020 | PIN domain-containing protein | - |
| AMC87_RS25630 (AMC87_PC00189) | 208994..209440 | - | 447 | WP_225882822 | DNA-binding protein | - |
| AMC87_RS25635 (AMC87_PC00191) | 209954..211144 | - | 1191 | WP_064820021 | DUF1173 domain-containing protein | - |
| AMC87_RS34255 | 211454..211711 | + | 258 | Protein_193 | toprim domain-containing protein | - |
| AMC87_RS25645 (AMC87_PC00192) | 212036..212976 | + | 941 | Protein_194 | DUF2493 domain-containing protein | - |
| AMC87_RS25650 (AMC87_PC00193) | 213061..213327 | + | 267 | WP_004676093 | hypothetical protein | - |
Host bacterium
| ID | 3213 | GenBank | NZ_CP013540 |
| Plasmid name | pRphaR630c | Incompatibility group | - |
| Plasmid size | 442592 bp | Coordinate of oriT [Strand] | 219515..219543 [+] |
| Host baterium | Rhizobium phaseoli strain R630 |
Cargo genes
| Drug resistance gene | - |
| Virulence gene | hsiC1/vipB |
| Metal resistance gene | - |
| Degradation gene | - |
| Symbiosis gene | nifX, nifN, nifE, nifK, nifD, nifH, nifS, nifW, fixA, fixB, fixC, fixX, nifA, nifB, nifZ, nifT, a9174_31165, nodD, nodJ, nodI, nodS, nodC, nodB, nodZ, fixG, fixO, fixN, mLTONO_5203, nodA |
| Anti-CRISPR | - |