Detailed information of oriT
oriT
The information of the oriT region
| oriTDB ID | 102764 |
| Name | oriT_pRspN113b |
| Organism | Rhizobium sp. N113 |
| Sequence Completeness | - |
| NCBI accession of oriT (coordinates [strand]) | NZ_CP013519 (215910..215938 [+], 29 nt) |
| oriT length | 29 nt |
| IRs (inverted repeats) | 14..19, 24..29 (CGTCGC..GCGACG) |
| Location of nic site | _ |
| Conserved sequence flanking the nic site |
_ |
| Note | Predicted by oriTfinder 2.0 |
oriT sequence
Download Length: 29 nt
>oriT_pRspN113b
AGGGCGCAATATACGTCGCTGTCGCGACG
AGGGCGCAATATACGTCGCTGTCGCGACG
Visualization of oriT structure
oriT secondary structure
Predicted by RNAfold.
Download structure file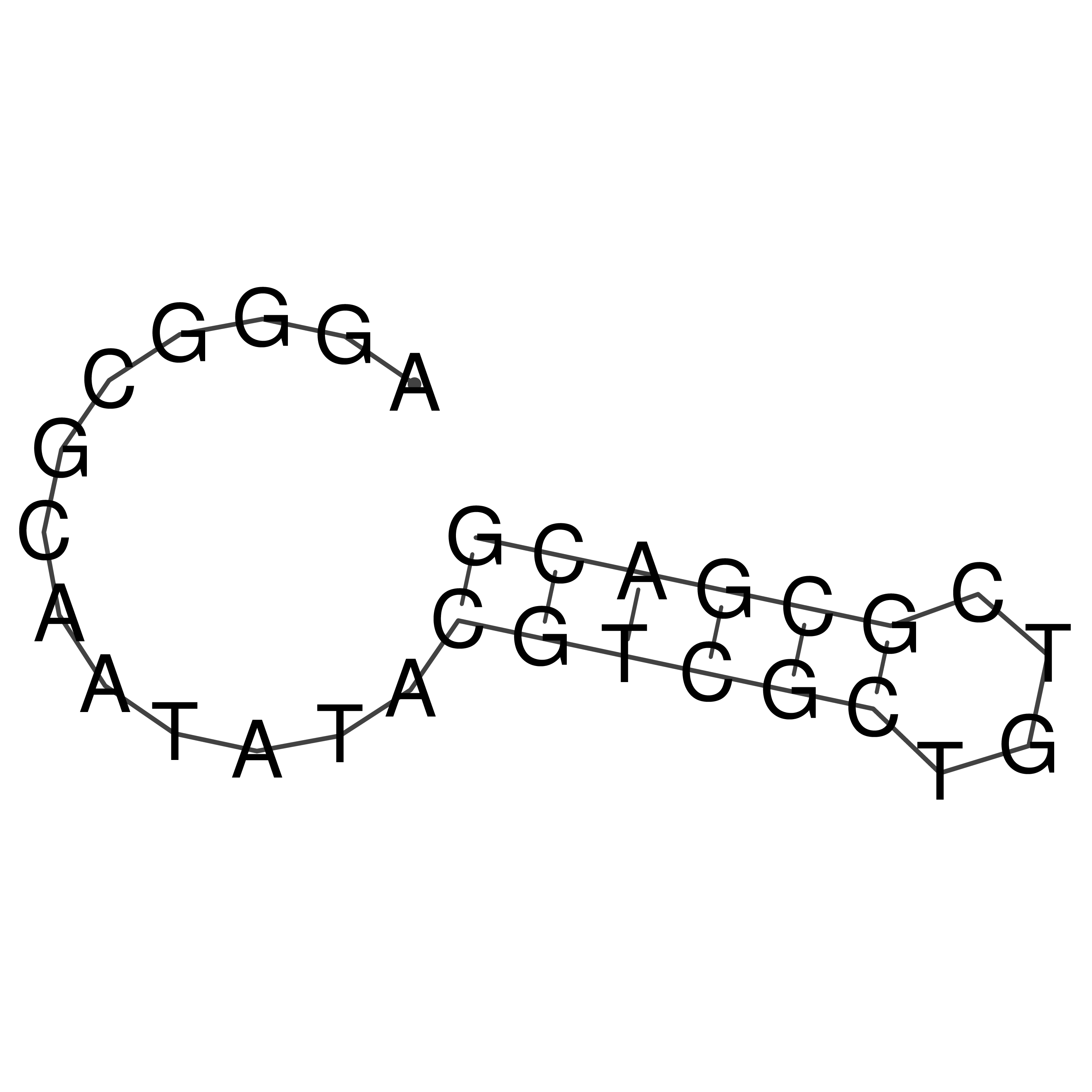
Relaxase
| ID | 2039 | GenBank | WP_064811989 |
| Name | traA_AMJ96_RS23935_pRspN113b |
UniProt ID | A0A192M522 |
| Length | 1565 a.a. | PDB ID | |
| Note | Predicted by oriTfinder 2.0 | ||
Relaxase protein sequence
Download Length: 1565 a.a. Molecular weight: 172913.26 Da Isoelectric Point: 7.2379
>WP_064811989.1 MULTISPECIES: Ti-type conjugative transfer relaxase TraA [Rhizobium]
MAIMFVRAQVISRGSGRSIVSAAAYRHRARMMDEQAGTSFSYRGGAGELMYEELALPDEIPDWLRSAISG
QSVSKASEVFWNAVDAFETRADAQLARELIIALPEELTRAENITLVRDFVRDNLTSKGMIADWVYHDKDG
NPHIHLMTTLRPLTEEGFGAKKVPVLGEGGKPLRVVTPDRPNGKIVYKVWAGDKETLNAWKIAWAETANR
HLALADHDIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGRELHFAPADLARRQEMADRLLAEPELLLKQ
LGNERSTFDERDIARALHRYVDDPTDFANIRARLMASDQLVILKPQEIEAETGKVSEPAMFTTREMLRIE
YDMAQSARVLSERRGFGVSERIVTVAIERVESIESGDPKTPFRLDAEQVDAVRHVTGDGDIAAIVGLAGA
GKSTLLAAARLAWEGEGHRVIGAALAGKAAEGLQHSSGIKSRTLASWELAWANGRDTLHRGDVLVIDEAG
MVASQQMARVLKIAEEAEVKVVLVGDAMQLQPIQAGAAFRAITERIGFAELAGVRRQREAWARNASRLFA
RGEVEKGLDAYARHGHLVEAGSREETIDRIVSDWAAARREAIERSTSEGGDGRLRGDELLVLAHTNDDVR
KLNEALRSVMTQEGALGESRSFRSERGAREFAAGDRIIFLENARFLEPRAKHSGPQYVKNGMLGTVVSTG
DKRGDPLLSILLDNGRKLVFSEDSYRHVDHGYAATIHKSQGATVDRTFVLATGMMDQHLTYVSMTRHRDR
VDLYAAKEDFAAKPEWGRKPRVDHAAGVTGELVETGEAKFRPDDEDADDSPYADVRADGGTVHRLWGVSL
PKALEEAGIQEGDTVMLRKDGVERVKVQITVVDEKTGHKHYEEREVDRNVWTASQVETASARQERIERES
HRSELFNPLVERLSRSGAKTTTLDFESEASYRAHANDFARRRGLDHLSLAAAEMEESLTRRWAWIAEKRE
QVAKLWERASVALGFAIERERRVAYNEERSQTMVEATSSDARTASHSVSGASAAETRYLIPPATSFVSSV
EEDARLAQLASPAWTEREVILRPLLQKIYRDPDAALVSLNALASDIGVAPRRLADDLAVAPGRLGRMRGS
ELIVDGRAAREERNVAVAGVKELLPIARAHATEFRRNAERFELREQTRRAHMSLSIPALSERAMARLMEI
EAVRRQGGDDAYKTAFALTAKDRSVVQEIKAVSEALTARFGWSAFSAKADAIAERNIVERMPEDLTDERR
GKLTRLFEAVRRFAEEQHLAERRDRSKIVAGASVDLRTGTEKGVGKENVPIPPMLAAVTEFKVPVDDEAR
SRALASPLYRQQRAALANAATTIWRDPAEVVGKIEELLQKGFAAERIGAAVTNNPAAYGALRGSDRLMDR
MLASGRERKEATRTVPEAAARLRALGAAYANALNSERQAITDERRRMAVAIPALSKAAEEALAHLTVEVS
KDSRKLNVSAASLDPGIGREFAAVSRALDERFGRNALVRGDKDIANVVPPAQRGAFAAMQERLKVLQQTV
RLQSSEQIIVERRQQTANRSRGINL
MAIMFVRAQVISRGSGRSIVSAAAYRHRARMMDEQAGTSFSYRGGAGELMYEELALPDEIPDWLRSAISG
QSVSKASEVFWNAVDAFETRADAQLARELIIALPEELTRAENITLVRDFVRDNLTSKGMIADWVYHDKDG
NPHIHLMTTLRPLTEEGFGAKKVPVLGEGGKPLRVVTPDRPNGKIVYKVWAGDKETLNAWKIAWAETANR
HLALADHDIRLDGRSYAEQGLDGIAQKHLGPEKAALARKGRELHFAPADLARRQEMADRLLAEPELLLKQ
LGNERSTFDERDIARALHRYVDDPTDFANIRARLMASDQLVILKPQEIEAETGKVSEPAMFTTREMLRIE
YDMAQSARVLSERRGFGVSERIVTVAIERVESIESGDPKTPFRLDAEQVDAVRHVTGDGDIAAIVGLAGA
GKSTLLAAARLAWEGEGHRVIGAALAGKAAEGLQHSSGIKSRTLASWELAWANGRDTLHRGDVLVIDEAG
MVASQQMARVLKIAEEAEVKVVLVGDAMQLQPIQAGAAFRAITERIGFAELAGVRRQREAWARNASRLFA
RGEVEKGLDAYARHGHLVEAGSREETIDRIVSDWAAARREAIERSTSEGGDGRLRGDELLVLAHTNDDVR
KLNEALRSVMTQEGALGESRSFRSERGAREFAAGDRIIFLENARFLEPRAKHSGPQYVKNGMLGTVVSTG
DKRGDPLLSILLDNGRKLVFSEDSYRHVDHGYAATIHKSQGATVDRTFVLATGMMDQHLTYVSMTRHRDR
VDLYAAKEDFAAKPEWGRKPRVDHAAGVTGELVETGEAKFRPDDEDADDSPYADVRADGGTVHRLWGVSL
PKALEEAGIQEGDTVMLRKDGVERVKVQITVVDEKTGHKHYEEREVDRNVWTASQVETASARQERIERES
HRSELFNPLVERLSRSGAKTTTLDFESEASYRAHANDFARRRGLDHLSLAAAEMEESLTRRWAWIAEKRE
QVAKLWERASVALGFAIERERRVAYNEERSQTMVEATSSDARTASHSVSGASAAETRYLIPPATSFVSSV
EEDARLAQLASPAWTEREVILRPLLQKIYRDPDAALVSLNALASDIGVAPRRLADDLAVAPGRLGRMRGS
ELIVDGRAAREERNVAVAGVKELLPIARAHATEFRRNAERFELREQTRRAHMSLSIPALSERAMARLMEI
EAVRRQGGDDAYKTAFALTAKDRSVVQEIKAVSEALTARFGWSAFSAKADAIAERNIVERMPEDLTDERR
GKLTRLFEAVRRFAEEQHLAERRDRSKIVAGASVDLRTGTEKGVGKENVPIPPMLAAVTEFKVPVDDEAR
SRALASPLYRQQRAALANAATTIWRDPAEVVGKIEELLQKGFAAERIGAAVTNNPAAYGALRGSDRLMDR
MLASGRERKEATRTVPEAAARLRALGAAYANALNSERQAITDERRRMAVAIPALSKAAEEALAHLTVEVS
KDSRKLNVSAASLDPGIGREFAAVSRALDERFGRNALVRGDKDIANVVPPAQRGAFAAMQERLKVLQQTV
RLQSSEQIIVERRQQTANRSRGINL
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4CP
| ID | 1692 | GenBank | WP_064811988 |
| Name | traG_AMJ96_RS23920_pRspN113b |
UniProt ID | _ |
| Length | 639 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 639 a.a. Molecular weight: 70745.97 Da Isoelectric Point: 9.5675
>WP_064811988.1 MULTISPECIES: Ti-type conjugative transfer system protein TraG [Rhizobium]
MGLRGKPHPSLLLVLVPIAVTTITIYIVGWRWPGLAAGMSGKIEHWFLRAAPVPPLLFGPLAGLLTVWAL
PLHRRRPVAMASLLYFLGVAAFYALREFGRLAPAVQAEVITWDRALSYLDMVAVIAAVAGFMAVAMSARI
SVVVPDEIKRARRGIFGDADWLPMRAAGKLFPPEGEIVVGERYRVDKEIVHALPFDANDRSTWGQGGKAP
LLTYRQDFDSTHMLFFAGSGGYKTTSNVVPTALRYSGPLICLDPSTEVAPMVAEHRARALKREVMVLDPT
NPIMGFNVLDGIEASKQKEEDIVGIAHMLLSESLRFESSTGSYFQNQAHNLLTGLLAHVMLSPEYEGRRS
LRSLRQIVSEPEPSVLAMLRDIQEHSASAFIRETLGVFTNMTEQTFSGVYSTASKDTQWLSLDSYAALVC
GNAFKSSDIVSGKKDVFLNIPASILRSYPGIARVIIGSLINAMVQADGAFQRRALFMLDEVDLLGYMRVL
EEARDRGRKYGISMMLMYQSVGQLERHFGKDGATSWIDGCAFASYAAIKALDTARNVSAQCGEMTVEVKG
SSRNIGWDTKNNASRRSENVTFQRRPLIMPHEITQSMRKDEQIIIVQGHSPIRCGRAIYFRRKEMDQAAK
VNRFVKPVL
MGLRGKPHPSLLLVLVPIAVTTITIYIVGWRWPGLAAGMSGKIEHWFLRAAPVPPLLFGPLAGLLTVWAL
PLHRRRPVAMASLLYFLGVAAFYALREFGRLAPAVQAEVITWDRALSYLDMVAVIAAVAGFMAVAMSARI
SVVVPDEIKRARRGIFGDADWLPMRAAGKLFPPEGEIVVGERYRVDKEIVHALPFDANDRSTWGQGGKAP
LLTYRQDFDSTHMLFFAGSGGYKTTSNVVPTALRYSGPLICLDPSTEVAPMVAEHRARALKREVMVLDPT
NPIMGFNVLDGIEASKQKEEDIVGIAHMLLSESLRFESSTGSYFQNQAHNLLTGLLAHVMLSPEYEGRRS
LRSLRQIVSEPEPSVLAMLRDIQEHSASAFIRETLGVFTNMTEQTFSGVYSTASKDTQWLSLDSYAALVC
GNAFKSSDIVSGKKDVFLNIPASILRSYPGIARVIIGSLINAMVQADGAFQRRALFMLDEVDLLGYMRVL
EEARDRGRKYGISMMLMYQSVGQLERHFGKDGATSWIDGCAFASYAAIKALDTARNVSAQCGEMTVEVKG
SSRNIGWDTKNNASRRSENVTFQRRPLIMPHEITQSMRKDEQIIIVQGHSPIRCGRAIYFRRKEMDQAAK
VNRFVKPVL
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4SS
T4SS were predicted by using oriTfinder2.
Region 1: 196149..205737
| Locus tag | Coordinates | Strand | Size (bp) | Protein ID | Product | Description |
|---|---|---|---|---|---|---|
| AMJ96_RS33645 | 192633..192859 | - | 227 | Protein_187 | chaperonin GroEL | - |
| AMJ96_RS23795 (AMJ96_PB00184) | 193154..194074 | + | 921 | WP_064811974 | zincin-like metallopeptidase domain-containing protein | - |
| AMJ96_RS23800 | 194185..194367 | - | 183 | WP_016737443 | hypothetical protein | - |
| AMJ96_RS23805 (AMJ96_PB00186) | 195139..195510 | - | 372 | WP_042120136 | hypothetical protein | - |
| AMJ96_RS23810 (AMJ96_PB00187) | 195609..196145 | + | 537 | WP_064811975 | hypothetical protein | - |
| AMJ96_RS23815 (AMJ96_PB00188) | 196149..196808 | + | 660 | WP_064811976 | lytic transglycosylase domain-containing protein | virB1 |
| AMJ96_RS23820 (AMJ96_PB00189) | 196805..197104 | + | 300 | WP_009997887 | TrbC/VirB2 family protein | virB2 |
| AMJ96_RS23825 (AMJ96_PB00190) | 197110..197448 | + | 339 | WP_009997888 | type IV secretion system protein VirB3 | virB3 |
| AMJ96_RS23830 (AMJ96_PB00191) | 197441..199807 | + | 2367 | WP_064811977 | VirB4 family type IV secretion system protein | virb4 |
| AMJ96_RS23835 (AMJ96_PB00192) | 199804..200505 | + | 702 | WP_064811978 | P-type DNA transfer protein VirB5 | virB5 |
| AMJ96_RS23840 (AMJ96_PB00193) | 200502..200735 | + | 234 | WP_010007459 | EexN family lipoprotein | - |
| AMJ96_RS23845 (AMJ96_PB00194) | 200739..201671 | + | 933 | WP_040111793 | type IV secretion system protein | virB6 |
| AMJ96_RS33650 (AMJ96_PB00195) | 201711..201992 | + | 282 | WP_080771758 | hypothetical protein | - |
| AMJ96_RS23850 (AMJ96_PB00196) | 201994..202665 | + | 672 | WP_064811979 | virB8 family protein | virB8 |
| AMJ96_RS23855 (AMJ96_PB00197) | 202662..203519 | + | 858 | WP_064811980 | P-type conjugative transfer protein VirB9 | virB9 |
| AMJ96_RS23860 (AMJ96_PB00198) | 203528..204700 | + | 1173 | WP_064811981 | type IV secretion system protein VirB10 | virB10 |
| AMJ96_RS23865 (AMJ96_PB00199) | 204709..205737 | + | 1029 | WP_010008207 | P-type DNA transfer ATPase VirB11 | virB11 |
| AMJ96_RS23870 (AMJ96_PB00200) | 205781..206359 | - | 579 | WP_064811982 | PIN domain-containing protein | - |
| AMJ96_RS23875 (AMJ96_PB00201) | 206349..206795 | - | 447 | WP_225881772 | DNA-binding protein | - |
| AMJ96_RS23880 (AMJ96_PB00203) | 207307..208497 | - | 1191 | WP_064811984 | DUF1173 domain-containing protein | - |
| AMJ96_RS33655 | 208808..209067 | + | 260 | Protein_207 | toprim domain-containing protein | - |
| AMJ96_RS23890 (AMJ96_PB00204) | 209453..209719 | + | 267 | WP_004676093 | hypothetical protein | - |
| AMJ96_RS23895 (AMJ96_PB00205) | 209716..210114 | + | 399 | WP_064811986 | type II toxin-antitoxin system VapC family toxin | - |
Host bacterium
| ID | 3207 | GenBank | NZ_CP013519 |
| Plasmid name | pRspN113b | Incompatibility group | - |
| Plasmid size | 435821 bp | Coordinate of oriT [Strand] | 215910..215938 [+] |
| Host baterium | Rhizobium sp. N113 |
Cargo genes
| Drug resistance gene | - |
| Virulence gene | hsiC1/vipB |
| Metal resistance gene | - |
| Degradation gene | - |
| Symbiosis gene | nifX, nifN, nifE, nifK, nifD, nifH, nifS, nifW, fixA, fixB, fixC, fixX, nifA, nifB, nifZ, nifT, nodD, nodJ, nodI, nodS, nodC, fixO, fixN, mLTONO_5203, nodA |
| Anti-CRISPR | - |