Detailed information of oriT
oriT
The information of the oriT region
| oriTDB ID | 101420 |
| Name | oriT_pAsa4 |
| Organism | Aeromonas salmonicida subsp. salmonicida strain RS534 |
| Sequence Completeness | - |
| NCBI accession of oriT (coordinates [strand]) | NZ_JYFF01000051 (16803..16932 [+], 130 nt) |
| oriT length | 130 nt |
| IRs (inverted repeats) | _ |
| Location of nic site | _ |
| Conserved sequence flanking the nic site |
_ |
| Note | Predicted by oriTfinder 2.0 |
oriT sequence
Download Length: 130 nt
>oriT_pAsa4
GTTAACCCGTTTGATCGCGTGATGAATGCGCTAAAAAGTCGAGGCCGTAAGAACGCCCACATTCTGAGCATCTTGCAGCTGGATTGGCCTGCGTCTGAATCGATCATCCATCGCCTGAGCGACTACATCA
GTTAACCCGTTTGATCGCGTGATGAATGCGCTAAAAAGTCGAGGCCGTAAGAACGCCCACATTCTGAGCATCTTGCAGCTGGATTGGCCTGCGTCTGAATCGATCATCCATCGCCTGAGCGACTACATCA
Visualization of oriT structure
oriT secondary structure
Predicted by RNAfold.
Download structure file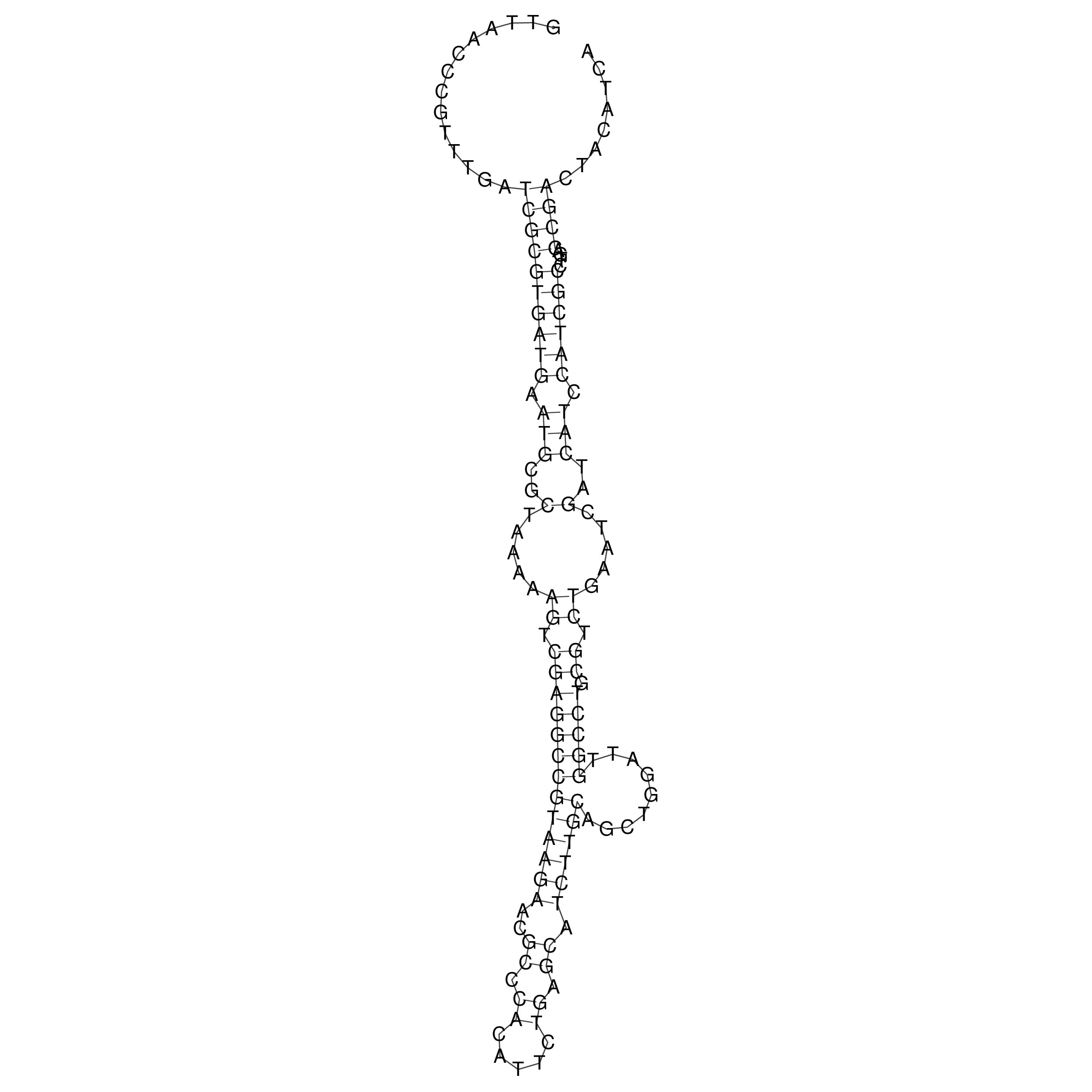
Relaxase
| ID | 1292 | GenBank | WP_236614860 |
| Name | mobH_UC37_RS20775_pAsa4 |
UniProt ID | _ |
| Length | 984 a.a. | PDB ID | |
| Note | Predicted by oriTfinder 2.0 | ||
Relaxase protein sequence
Download Length: 984 a.a. Molecular weight: 107305.59 Da Isoelectric Point: 4.7871
>WP_236614860.1 MobH family relaxase [Aeromonas salmonicida]
MDEEDIPRYPPFAKGLPVAPIDKILATQAELIEKVRNSLGFTIEDFNRLVLPVIHRYAAFVHLLPASEAH
HHRGAGGLFRHGLEVAFWAAQASESVIFSIEGTPKQRRDNEPRWRLASCFSGLLHDVGKPLADVSITDKN
GVVTWNPYFESLHDWAGRNHVDRYFIRWREKRHKRHEQFSLLAVDRIIPVATREYLSESGPLIIEAMLEA
ISGTSVNQPVTKLMLRADQESVSRDLKQNRLNVDEFSYGVPVERYVFDAIRRLVKTGKWKVNEPGAKVWH
LQQGVFIAWRNLGDLYDLISHDKIPGIPRDPDTLADILIERGFAVPNTVQEKGDRAYYRYWEVLPEMIQE
AAGSIKILMLRLESNELVFTTEPPAAVAGEVVGDVADAVIELIDPDEASDADDESASGMSESLLSAEQEA
MNALAGLGFGDAMEILGGTASDDNATQPAPVVDTTPPAKPAKGAGGRGGKNQAKKTAPAAPEQQQPEPSP
QEIAKSTPPLAVENPLQAIMDVGGGLGGLDFPFDAFVAGTSMSDEPSQALAPEPKQDVANPDNPDTPNLG
LMNQVFPNFMNDESTGDVGGMDLPPAWAIEEIPSFHAYEGEVGQPGNQFVSEELAGADAPDAKGELLTLM
ATFGEAGPILERAILPVLEGKATLGEVLCLMKGQAVILYPEGARALGAPSEILTALFHAQAIVPDPVMSG
RKVQDFNGVKAIVLTEQLSSAFIAAIKQAESLLGGYQDAFELVASPEVKKTQSKKNRGQRKTSRSESSGE
DSHAASPERAQVEEKRVIADAQLIDVSVEPPSPPVDTTPPPDKVVPRKESRGKEKVDKPIQPAPTTKPTE
GTQNLARLPPREQPKPESQQKQARVIDVGNIALPGPDLPEELSPRSIVKEETVDEALYLPPKMTPEKAIQ
MLKEMIKNRSGRWLVSAVLEEEGFLTTSDKAFEVIAGEYTGISKHVLGGTLRRAQRRPLLKQRQGKLYLE
VDKS
MDEEDIPRYPPFAKGLPVAPIDKILATQAELIEKVRNSLGFTIEDFNRLVLPVIHRYAAFVHLLPASEAH
HHRGAGGLFRHGLEVAFWAAQASESVIFSIEGTPKQRRDNEPRWRLASCFSGLLHDVGKPLADVSITDKN
GVVTWNPYFESLHDWAGRNHVDRYFIRWREKRHKRHEQFSLLAVDRIIPVATREYLSESGPLIIEAMLEA
ISGTSVNQPVTKLMLRADQESVSRDLKQNRLNVDEFSYGVPVERYVFDAIRRLVKTGKWKVNEPGAKVWH
LQQGVFIAWRNLGDLYDLISHDKIPGIPRDPDTLADILIERGFAVPNTVQEKGDRAYYRYWEVLPEMIQE
AAGSIKILMLRLESNELVFTTEPPAAVAGEVVGDVADAVIELIDPDEASDADDESASGMSESLLSAEQEA
MNALAGLGFGDAMEILGGTASDDNATQPAPVVDTTPPAKPAKGAGGRGGKNQAKKTAPAAPEQQQPEPSP
QEIAKSTPPLAVENPLQAIMDVGGGLGGLDFPFDAFVAGTSMSDEPSQALAPEPKQDVANPDNPDTPNLG
LMNQVFPNFMNDESTGDVGGMDLPPAWAIEEIPSFHAYEGEVGQPGNQFVSEELAGADAPDAKGELLTLM
ATFGEAGPILERAILPVLEGKATLGEVLCLMKGQAVILYPEGARALGAPSEILTALFHAQAIVPDPVMSG
RKVQDFNGVKAIVLTEQLSSAFIAAIKQAESLLGGYQDAFELVASPEVKKTQSKKNRGQRKTSRSESSGE
DSHAASPERAQVEEKRVIADAQLIDVSVEPPSPPVDTTPPPDKVVPRKESRGKEKVDKPIQPAPTTKPTE
GTQNLARLPPREQPKPESQQKQARVIDVGNIALPGPDLPEELSPRSIVKEETVDEALYLPPKMTPEKAIQ
MLKEMIKNRSGRWLVSAVLEEEGFLTTSDKAFEVIAGEYTGISKHVLGGTLRRAQRRPLLKQRQGKLYLE
VDKS
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
T4CP
| ID | 905 | GenBank | WP_011899407 |
| Name | traD_UC37_RS20780_pAsa4 |
UniProt ID | _ |
| Length | 621 a.a. | PDB ID | _ |
| Note | Predicted by oriTfinder 2.0 | ||
T4CP protein sequence
Download Length: 621 a.a. Molecular weight: 68931.34 Da Isoelectric Point: 6.8339
>WP_011899407.1 MULTISPECIES: conjugative transfer system coupling protein TraD [Gammaproteobacteria]
MTYDPLAYEMPWRPNYEMSAVFGWVAASVGALAVQQITDMPPEPFYWMTGICGVMTMARLPKAIKLHLLQ
KHLKGRDLEFISIKELQKKVQASPEDMWLGYGFAWENRHAQRVFEILKRDWTSIVGTESTTSKIVRTIRG
KKKKEVPIGQPWIHGVEPKEEHLMQPLKHTEGHSLIVGTTGSGKTRMFDTLISQAILRGEAVIIIDPKGD
KEMRDNARRACEAMGQAERFVSFHPAFPEESVRIDPLRNFTRVTEIASRLAALIPSEGGGDPFKSFGWQA
LNNIAQGLILAYDRPNLIKLRRFLEGGADGLVIKAVQAYAERVMPDWEAAAAPYLEKAANGSRSKLAVAH
MAFYNNVIQPEHPSSELEGLLNMFKHDATHFSKMVSNLLPIMNMLTSGELGPLLSPDATDLSDERQITDS
AKIINNAQVAYLGLDSLTDNMVGSALGSIFLSDLTAVAGDRYNYGVNNLPVNIFVDEAAEVINDPFIQLL
NKGRGAKLRLFVATQTFADFAARLGSKDKALQVLGNINNVFALRIVDAETQEYIAENLPKTRLKYVMRTQ
GQNTDGSEPIMHGGNQGERLMEEEADLFPAQLLGMLPNLEYIAKISGGKIVKGRLPILTEK
MTYDPLAYEMPWRPNYEMSAVFGWVAASVGALAVQQITDMPPEPFYWMTGICGVMTMARLPKAIKLHLLQ
KHLKGRDLEFISIKELQKKVQASPEDMWLGYGFAWENRHAQRVFEILKRDWTSIVGTESTTSKIVRTIRG
KKKKEVPIGQPWIHGVEPKEEHLMQPLKHTEGHSLIVGTTGSGKTRMFDTLISQAILRGEAVIIIDPKGD
KEMRDNARRACEAMGQAERFVSFHPAFPEESVRIDPLRNFTRVTEIASRLAALIPSEGGGDPFKSFGWQA
LNNIAQGLILAYDRPNLIKLRRFLEGGADGLVIKAVQAYAERVMPDWEAAAAPYLEKAANGSRSKLAVAH
MAFYNNVIQPEHPSSELEGLLNMFKHDATHFSKMVSNLLPIMNMLTSGELGPLLSPDATDLSDERQITDS
AKIINNAQVAYLGLDSLTDNMVGSALGSIFLSDLTAVAGDRYNYGVNNLPVNIFVDEAAEVINDPFIQLL
NKGRGAKLRLFVATQTFADFAARLGSKDKALQVLGNINNVFALRIVDAETQEYIAENLPKTRLKYVMRTQ
GQNTDGSEPIMHGGNQGERLMEEEADLFPAQLLGMLPNLEYIAKISGGKIVKGRLPILTEK
Protein domains
Predicted by InterproScan.
Protein structure
No available structure.
Host bacterium
| ID | 1864 | GenBank | NZ_JYFF01000051 |
| Plasmid name | pAsa4 | Incompatibility group | - |
| Plasmid size | 18888 bp | Coordinate of oriT [Strand] | 16803..16932 [+] |
| Host baterium | Aeromonas salmonicida subsp. salmonicida strain RS534 |
Cargo genes
| Drug resistance gene | - |
| Virulence gene | - |
| Metal resistance gene | - |
| Degradation gene | - |
| Symbiosis gene | - |
| Anti-CRISPR | - |